In this module, we extend our simple linear regression and ANOVA models to cases where we have more than one predictor variable. The same approach can be used with combinations of continuous and categorical variables. If all of our predictors variables are continuous, we typically describe this as “multiple linear regression”. If our predictors are combinations of continuous and categorical variables, we typically describe this as “analysis of covariance”, or ANCOVA.
Multiple linear regression and ANCOVA are pretty straightforward generalizations of the simple linear regression and ANOVA approach that we have considered previously (i.e., Model I regressions, with our parameters estimated using the criterion of OLS). In multiple linear regression and ANCOVA, we are looking to model a response variable in terms of more than one predictor variable so that we can evaluate the effects of several different explanatory variables. When we do multiple linear regression, we are, essentially, looking at the relationship between each of two or more continuous predictor variables and a continuous response variable while holding the effect of all other predictor variables constant. When we do ANCOVA, we are effectively looking at the relationship between one or more continuous predictor variables and a continuous response variable within each of one or more categorical groups.
To characterize this using formulas analogous to those we have used before…
We thus now need to estimate several\(\beta\) coefficients for our regression model - one for the intercept plus one for each predictor variable in our model, and, instead of a “line”” of best fit, we are determining a multidimensional “surface” of best fit. The criteria we typically use for estimating best fit is analogous to that we’ve used before, i.e., ordinary least squares, where we want to minimize the multidimensional squared deviation between our observed and predicted values:
Estimating our set of coefficients for multiple regression is actually done using matrix algebra, which we do not need to explore thoroughly (but see the “digression” below). The lm() function will implement this process for us directly.
NOTE: Besides the least squares approach to parameter estimation, we might also use other approaches, including maximum likelihood and Bayesian approaches. These are mostly beyond the scope of what we will discuss in this class, but the objective is the same… to use a particular criterion to estimate parameter values for describing the relationship between our predictor and response variables, as well as for estimating the amount of uncertainty in those parameter values. It is worth noting that for many common population parameters (such as the mean), as well as for regression slopes and/or factor effects in certain linear models, OLS and ML estimators turn out to be exactly the same when the assumptions behind OLS are met (i.e., normally distributed variables and normally distributed error terms). When response variables or residuals are not normally distributed (e.g., where we have binary or categorical response variables), we use ML or Bayesian approaches, rather than OLS, for parameter estimation.
Let’s work some examples!
21.4 Multiple Regression
Continous Response Variable with More than One Continuous Predictor
We will start by taking a digression to construct a dataset ourselves of some correlated random normal continuous variables. The following bit of code will let us do that. See also this post for more information on generating toy data with a particular correlation structure. First, we define a matrix of correlations, R, among our variables (you can play with the values in this matrix, but it must be symmetric):
Second, we generate a dataset of random normal variables where each has a defined mean and standard deviation and then bundle these into a dataframe (“original”):
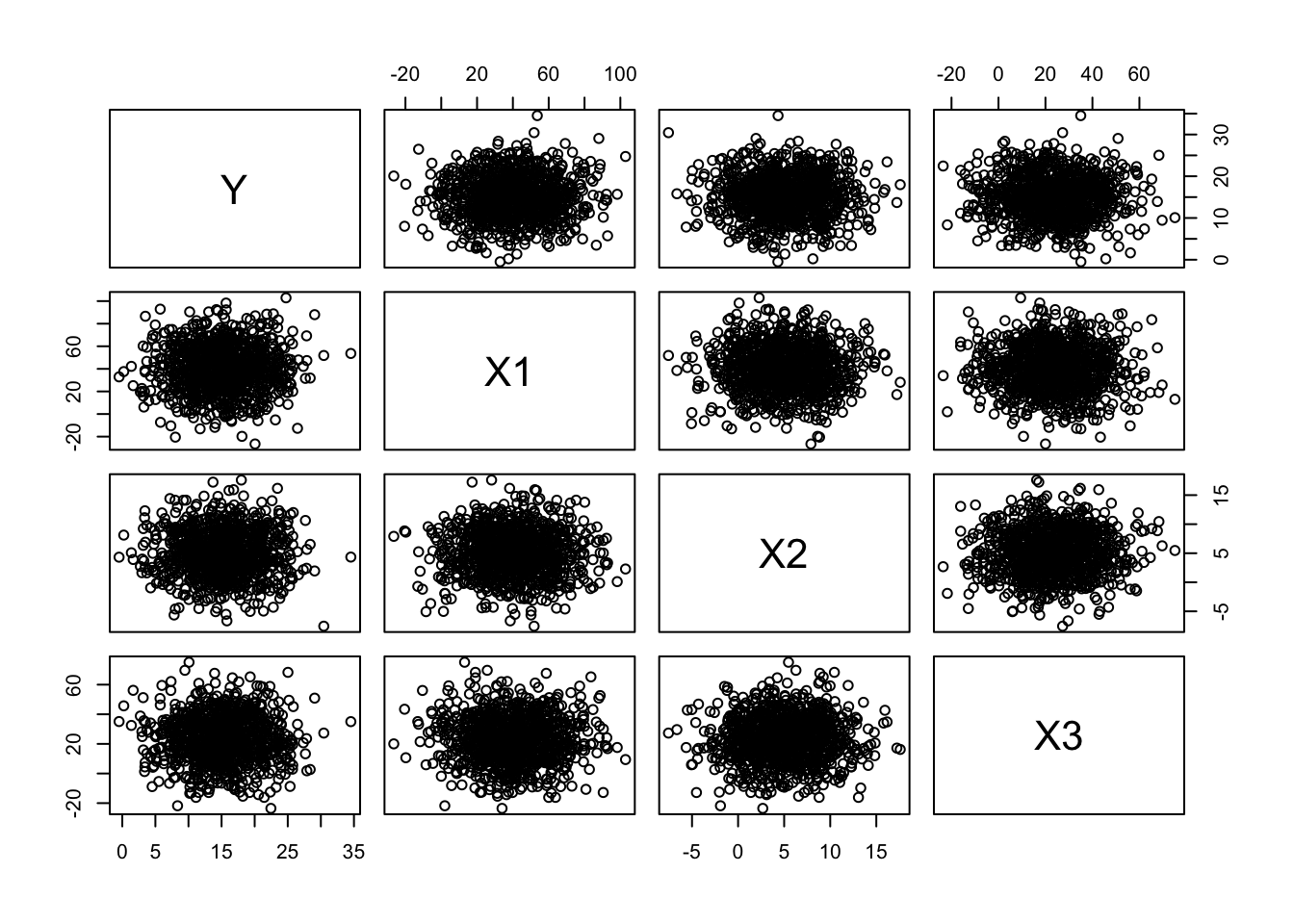
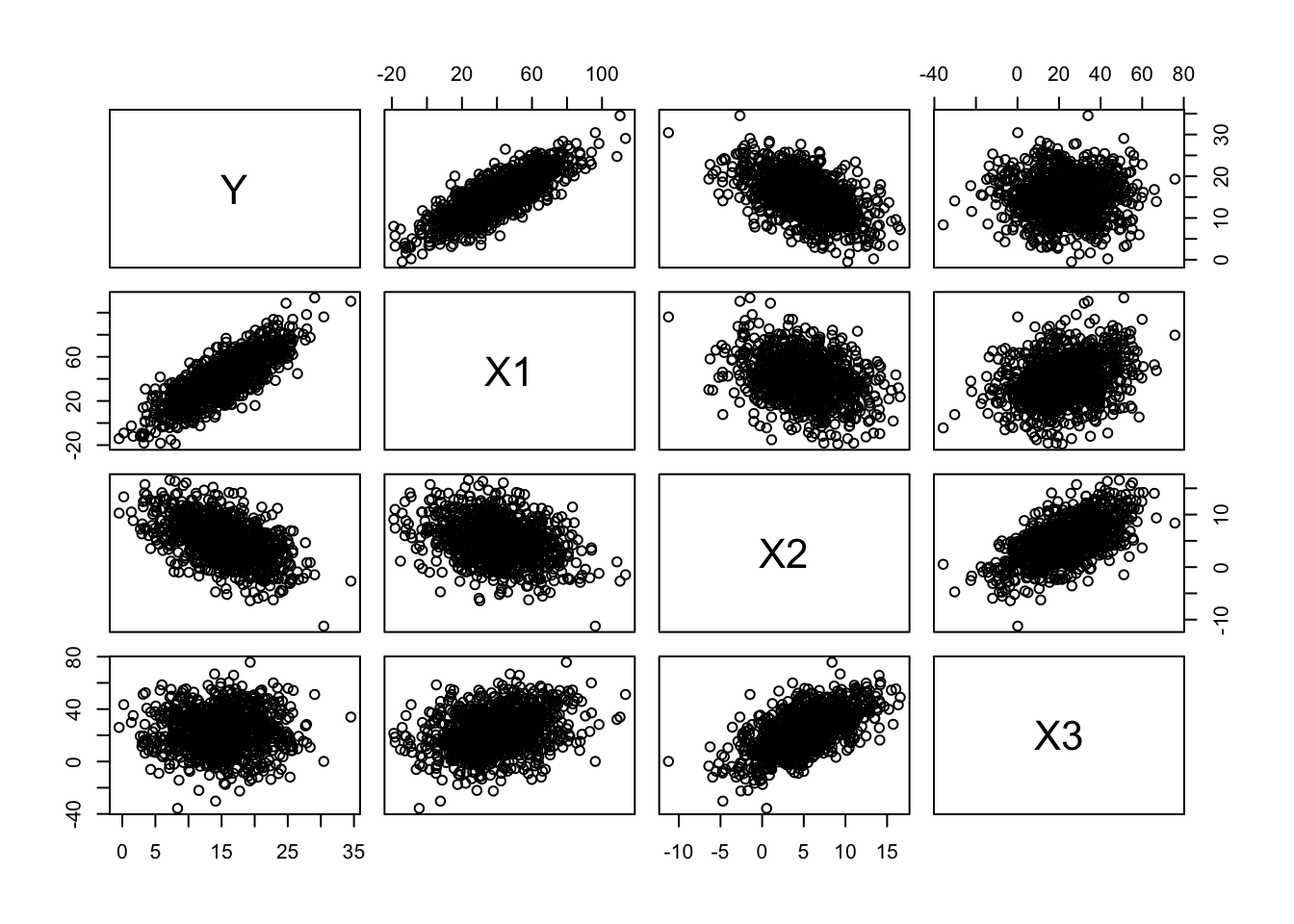
n <-1000k <-4original <-NULLv <-NULLmu <-c(15, 40, 5, 23) # vector of variable meanss <-c(5, 20, 4, 15) # vector of variable SDsfor (i in1:k) { v <-rnorm(n, mu[i], s[i]) original <-cbind(original, v)}original <-as.data.frame(original)names(original) <-c("Y", "X1", "X2", "X3")head(original)
# make quick bivariate plots for each pair of variablesplot(original)
# using `pairs(original)` would do the same
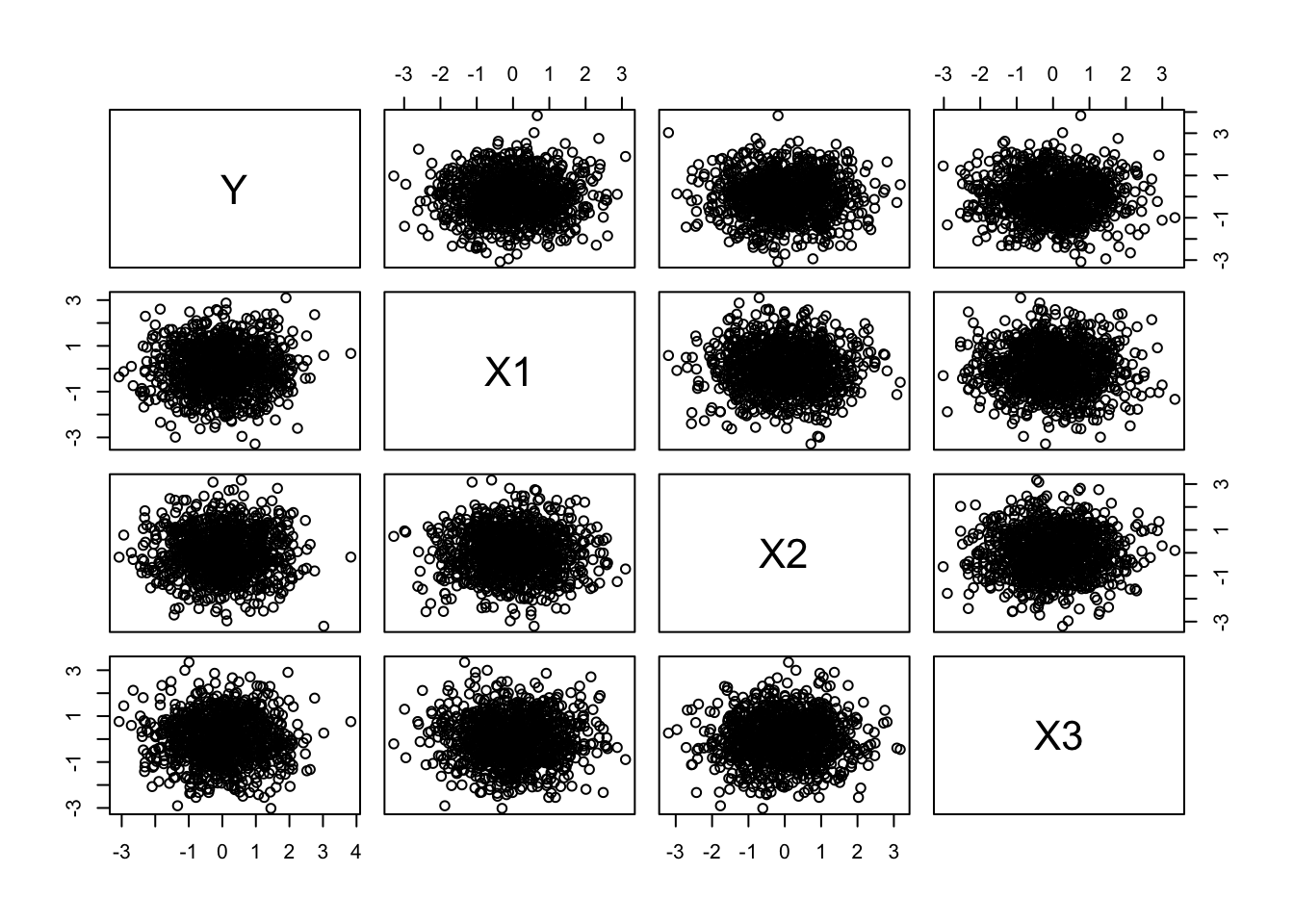
Now, let’s normalize and standardize our variables by subtracting the relevant means and dividing by the standard deviation. This converts them to \(Z\) scores from a standard normal distribution.
Now run the following… note how we use the apply() and sweep() functions here. Cool, eh?
means <-apply(original, 2, FUN ="mean") # returns a vector of means, where we are taking this across dimension 2 of the array "orig"means
## Y X1 X2 X3
## 15.086155 40.082699 5.001562 22.793213
normalized <-sweep(original, 2, STATS = means, FUN ="-") # 2nd dimension is columns, removing array of means, function = subtractnormalized <-sweep(normalized, 2, STATS = stdevs, FUN ="/") # 2nd dimension is columns, scaling by array of sds, function = dividehead(normalized) # now a dataframe of Z scores
M <-as.matrix(normalized) # define M as our matrix of normalized variables
With apply(), we apply a function to a specified margin of an array or matrix (1 = row, 2 = column), and with sweep() we then perform whatever function is specified by FUN= on all of the elements in an array specified by the given margin.
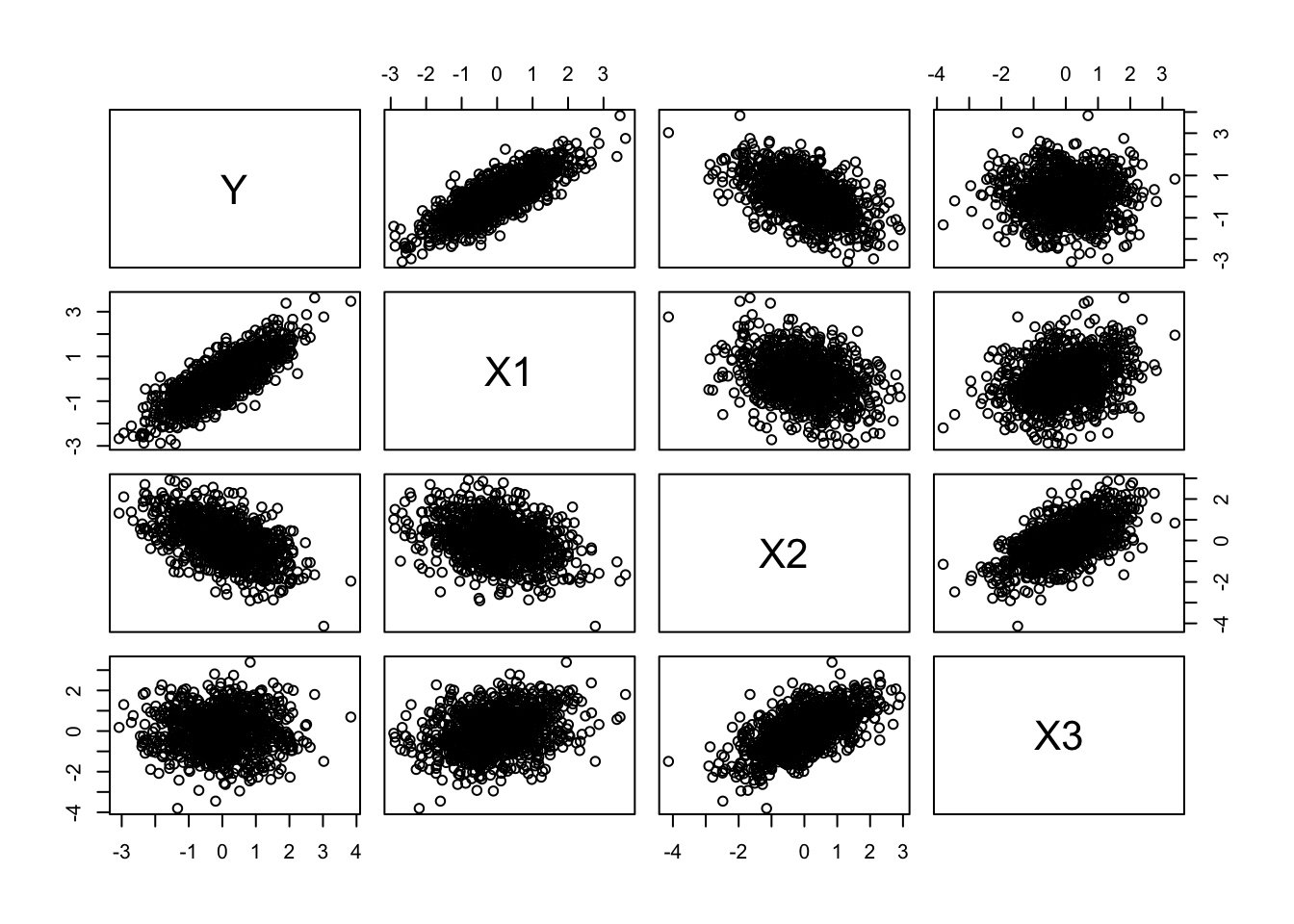
Next, we take what is called the Cholesky decomposition of our correlation matrix, R, and then multiply our normalized data matrix by the decomposition matrix to yield a transformed dataset with the specified correlation among variables. The Cholesky decomposition breaks certain symmetric matrices into two such that:
\(R = U \cdot U^T\)
U <-chol(R)newM <- M %*% Unew <-as.data.frame(newM)names(new) <-c("Y", "X1", "X2", "X3")cor(new) # note that is correlation matrix is what we are aiming for!
plot(new) # note the axis scales; using `pairs(new)` would plot the same
Finally, we can scale these back out to the mean and distribution of our original random variables.
d <-sweep(new, 2, STATS = stdevs, FUN ="*") # scale back out to original mean...d <-sweep(d, 2, STATS = means, FUN ="+") # and standard deviationhead(d)
We now have our own dataframe, d, comprising correlated random variables in original units!
Let’s explore this dataset, first with single and then with multivariate regression.
CHALLENGE
Start off by making three bivariate scatterplots in {ggplot2} using the dataframe of three predictor variables (X1, X2, and X3) and one response variable (Y) that we generated above (or download it from “https://raw.githubusercontent.com/difiore/ada-datasets/main/multiple_regression.csv”)
f <-"https://raw.githubusercontent.com/difiore/ada-datasets/main/multiple_regression.csv"d <-read_csv(f, col_names =TRUE)
## Rows: 1000 Columns: 4
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (4): Y, X1, X2, X3
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Show Code
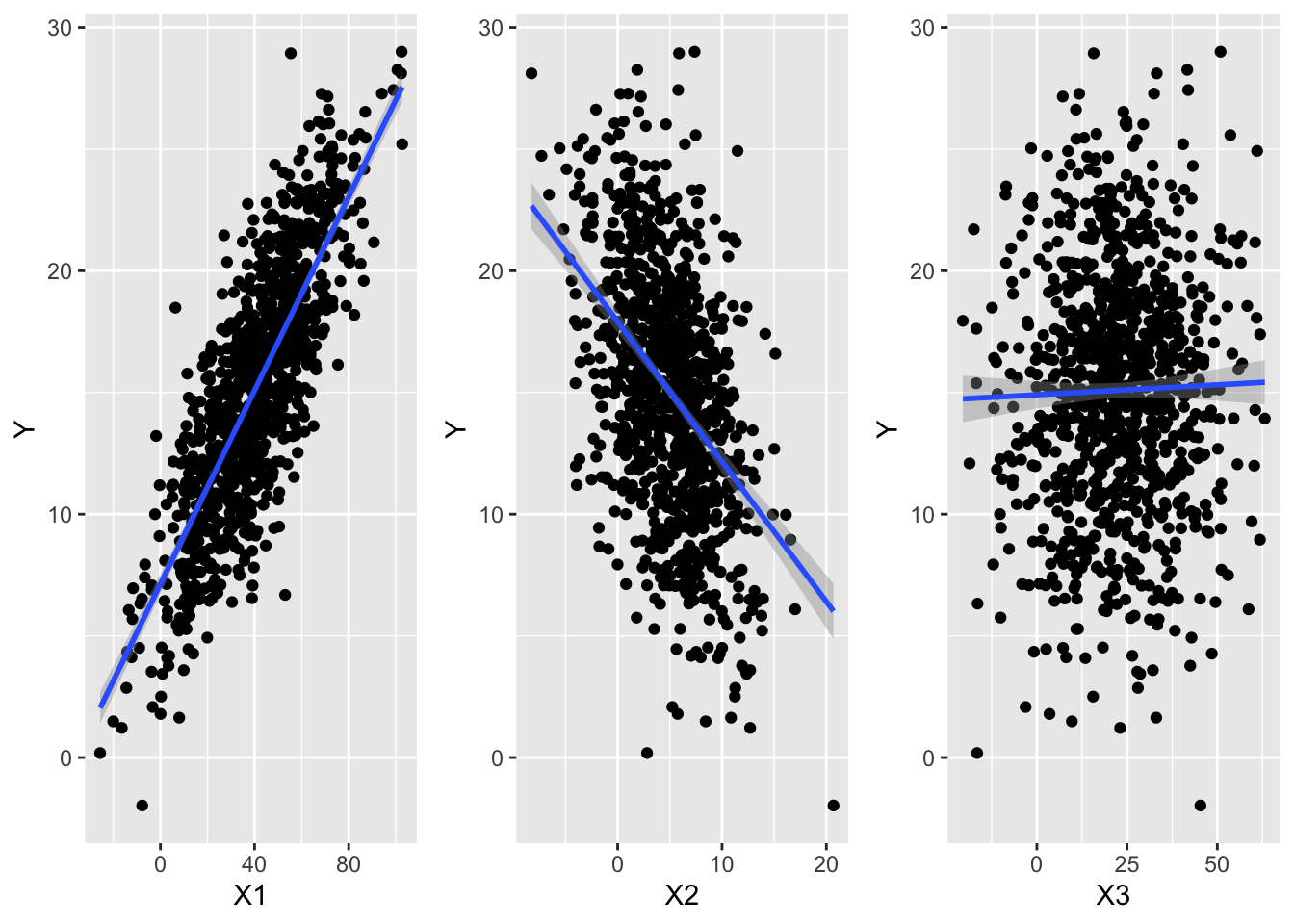
g1 <-ggplot(data = d, aes(x = X1, y = Y)) +geom_point() +geom_smooth(method ="lm", formula = y ~ x)g2 <-ggplot(data = d, aes(x = X2, y = Y)) +geom_point() +geom_smooth(method ="lm", formula = y ~ x)g3 <-ggplot(data = d, aes(x = X3, y = Y)) +geom_point() +geom_smooth(method ="lm", formula = y ~ x)grid.arrange(g1, g2, g3, ncol =3)
Then, using simple linear regression as implemented with lm(), how does the response variable (Y) vary with each predictor variable (X1, X2, X3)? Are the \(\beta_1\) coefficients for each bivariate significant? How much of the variation in Y does each predictor explain in a simple bivariate linear model?
Show Code
m1 <-lm(data = d, formula = Y ~ X1)summary(m1)
Show Output
##
## Call:
## lm(formula = Y ~ X1, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.9848 -2.1238 0.0731 2.1175 10.7924
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.132691 0.213888 33.35 <2e-16 ***
## X1 0.198846 0.004785 41.55 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.012 on 998 degrees of freedom
## Multiple R-squared: 0.6337, Adjusted R-squared: 0.6334
## F-statistic: 1727 on 1 and 998 DF, p-value: < 2.2e-16
Show Code
m2 <-lm(data = d, formula = Y ~ X2)summary(m2)
Show Output
##
## Call:
## lm(formula = Y ~ X2, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -16.1071 -3.0301 0.1099 2.9888 15.3328
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 17.91187 0.22465 79.73 <2e-16 ***
## X2 -0.57531 0.03579 -16.07 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.435 on 998 degrees of freedom
## Multiple R-squared: 0.2057, Adjusted R-squared: 0.2049
## F-statistic: 258.4 on 1 and 998 DF, p-value: < 2.2e-16
Show Code
m3 <-lm(data = d, formula = Y ~ X3)summary(m3)
Show Output
##
## Call:
## lm(formula = Y ~ X3, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -17.2471 -3.2823 0.0706 3.2325 13.9029
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 14.906854 0.288255 51.714 <2e-16 ***
## X3 0.008163 0.010715 0.762 0.446
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.975 on 998 degrees of freedom
## Multiple R-squared: 0.0005812, Adjusted R-squared: -0.0004202
## F-statistic: 0.5804 on 1 and 998 DF, p-value: 0.4463
In simple linear regression, Y has a significant, positive relationship with X1, a signficant negative relationship with X2, and no significant bivariate relationship with X3.
Now let’s move on to doing actual multiple regression. To review, with multiple regression, we are looking to model a response variable in terms of two or more predictor variables so we can evaluate the effect of each of several explanatory variables while holding the others constant.
Using lm() and formula notation, we can fit a model with all three predictor variables. The + sign is used to add additional predictors to our model.
m <-lm(data = d, formula = Y ~ X1 + X2 + X3)coef(m)
##
## Call:
## lm(formula = Y ~ X1 + X2 + X3, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -9.3943 -1.7442 -0.1112 1.8602 10.6242
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.148858 0.254643 35.928 < 2e-16 ***
## X1 0.200496 0.005680 35.297 < 2e-16 ***
## X2 -0.197944 0.033890 -5.841 7.03e-09 ***
## X3 -0.049311 0.009235 -5.339 1.15e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.7 on 996 degrees of freedom
## Multiple R-squared: 0.7062, Adjusted R-squared: 0.7053
## F-statistic: 798.1 on 3 and 996 DF, p-value: < 2.2e-16
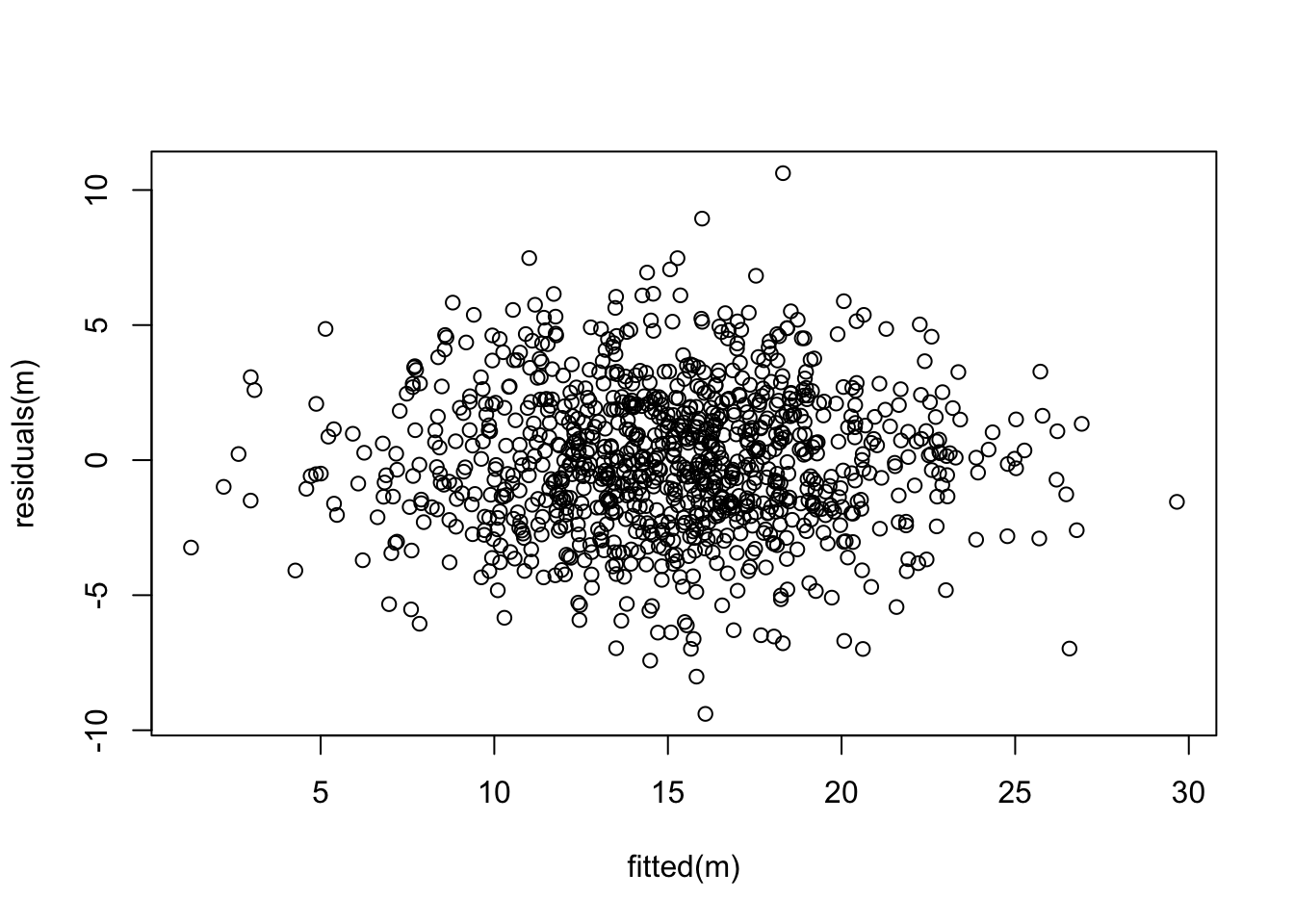
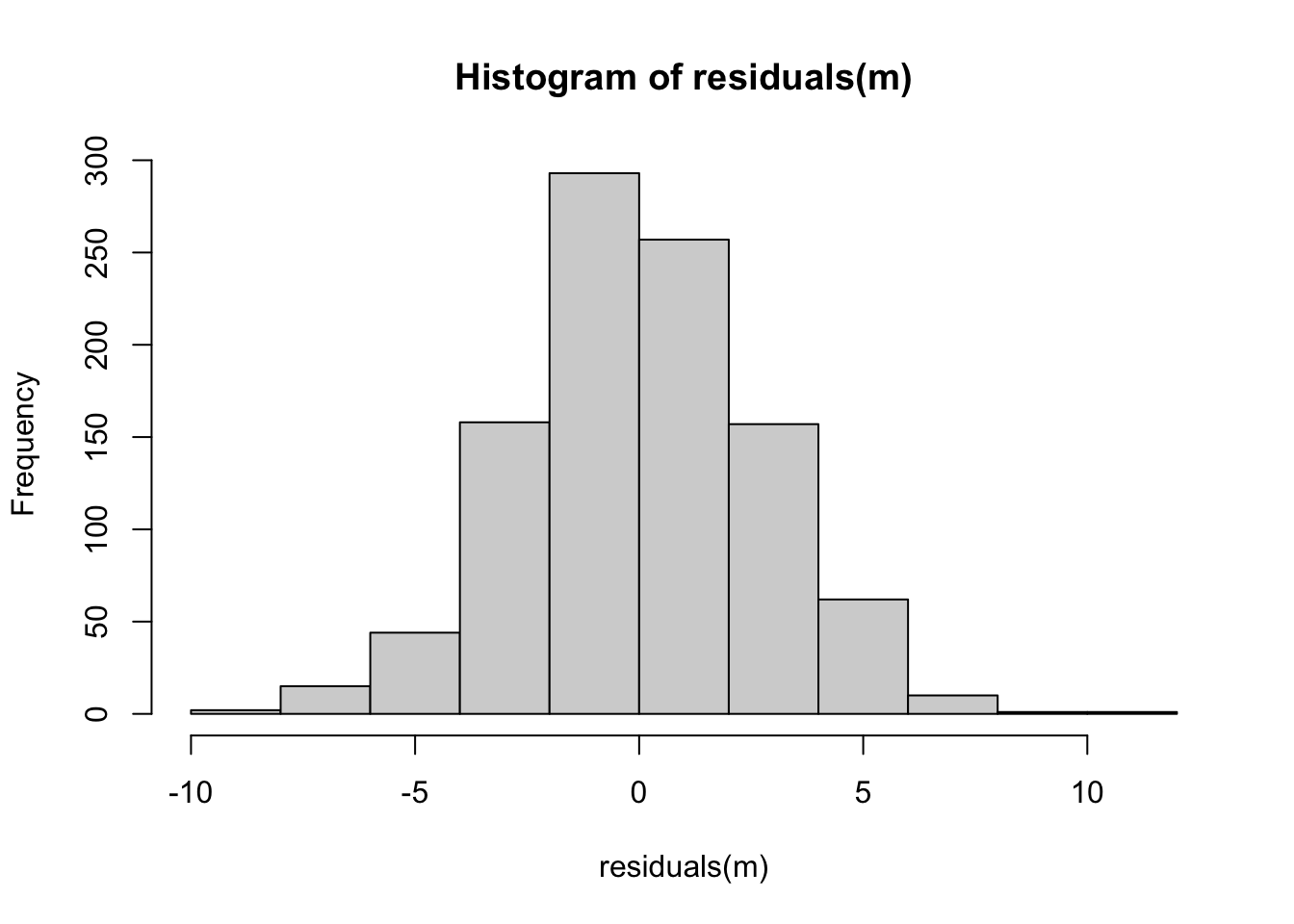
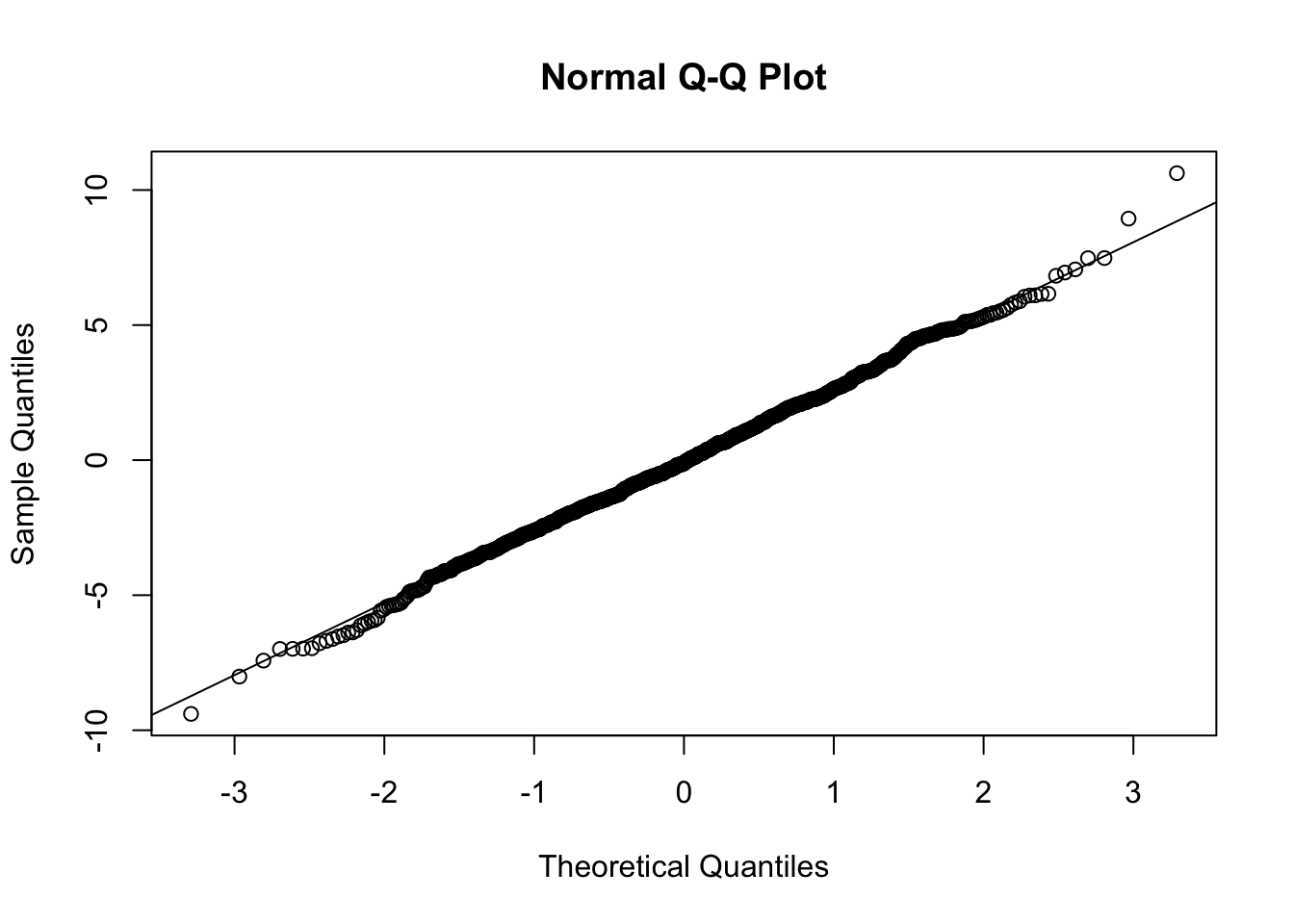
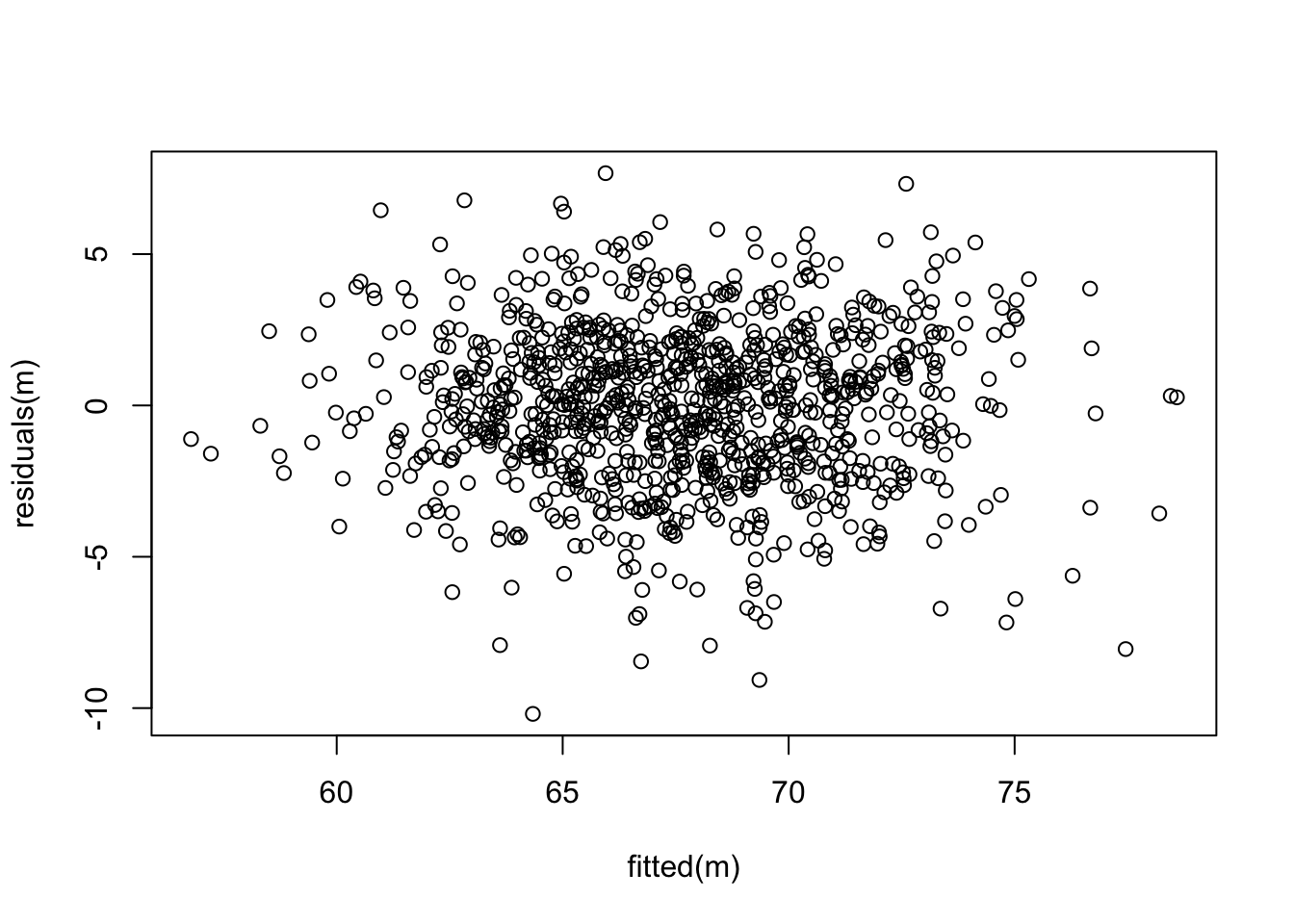
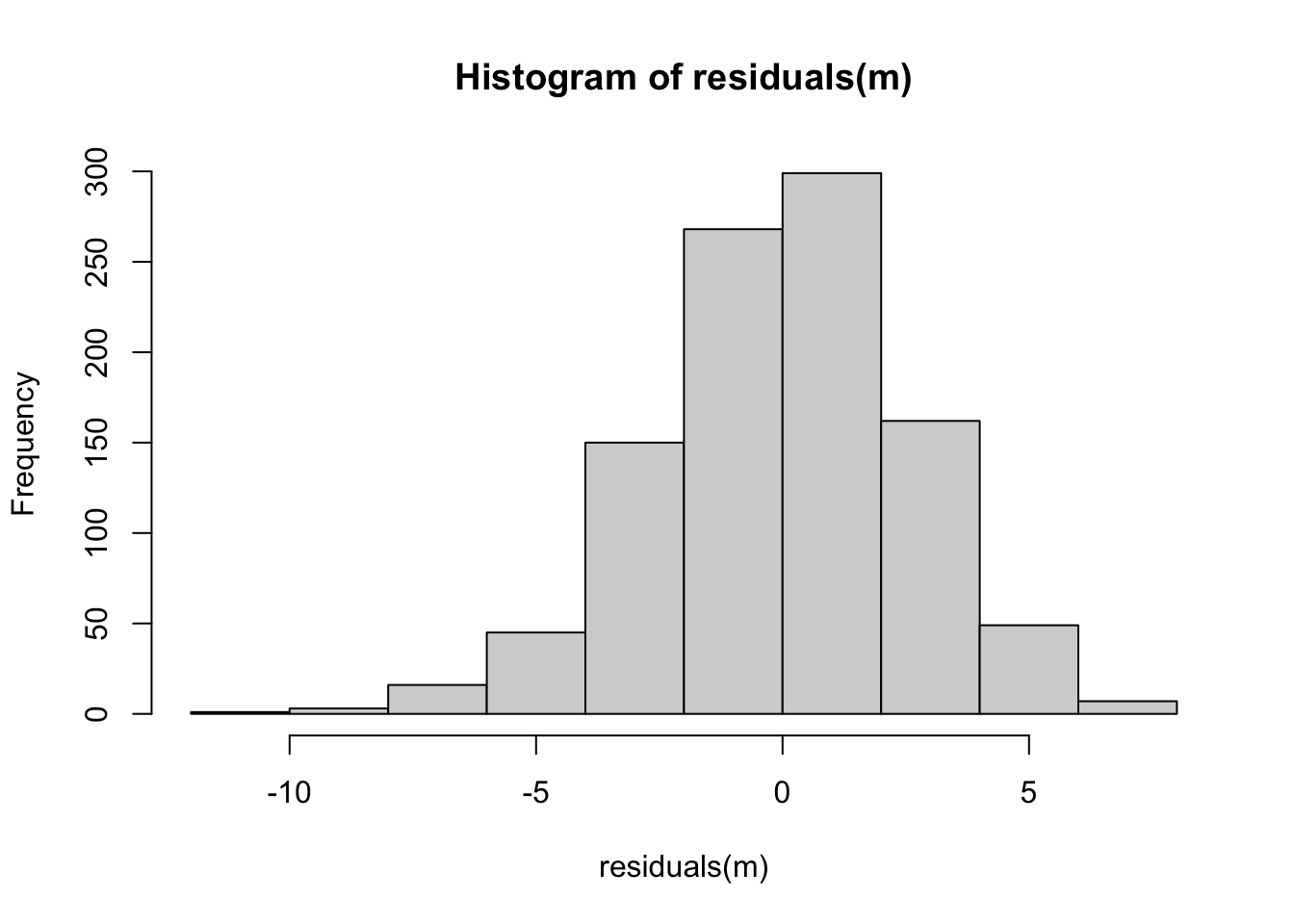
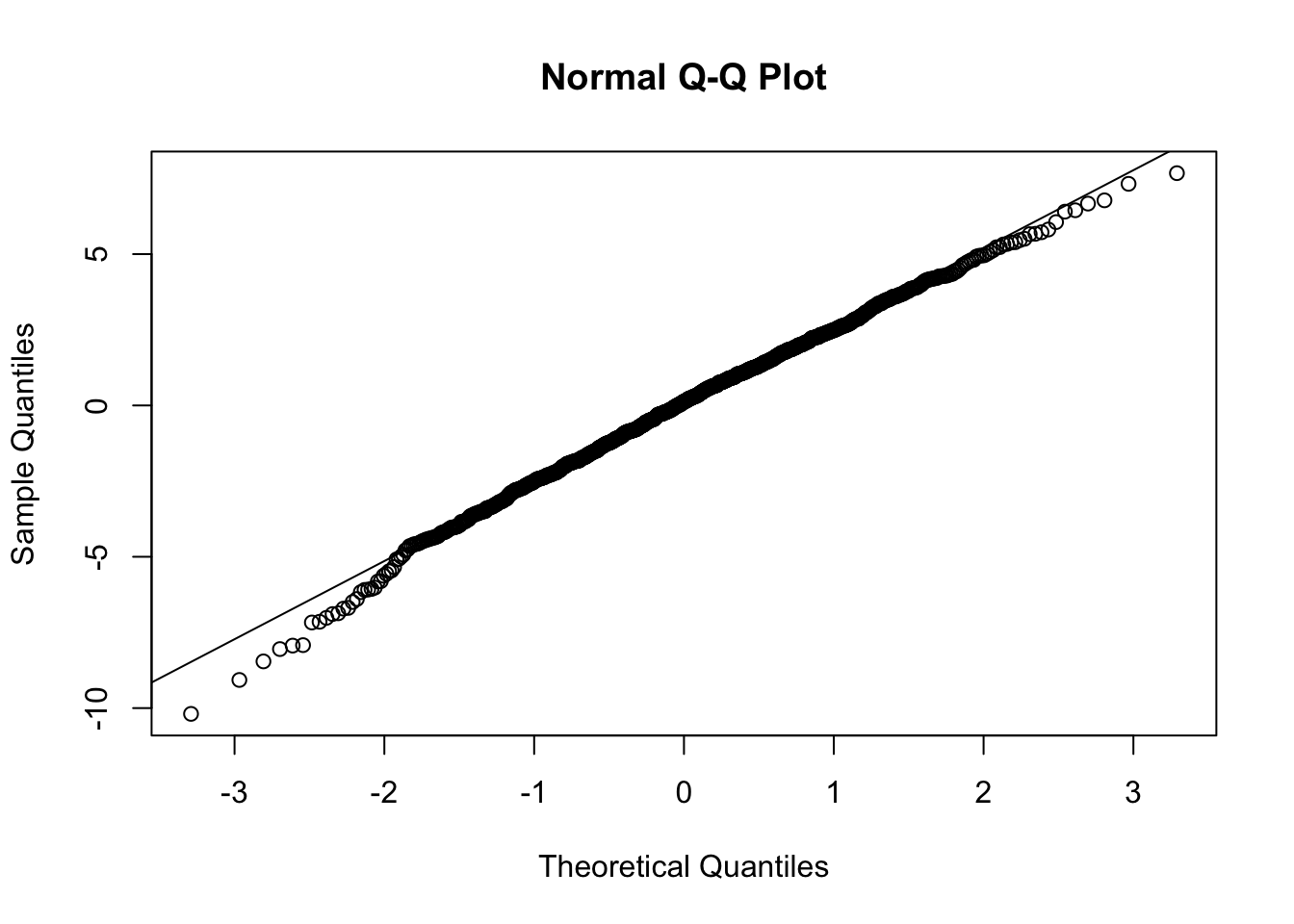
Next, let’s check if our residuals are random normal…
Show Code
plot(fitted(m), residuals(m))
Show Code
hist(residuals(m))
Show Code
qqnorm(residuals(m))qqline(residuals(m))
What does this output tell us? First off, the results of the omnibus F test tells us that the overall model is significant; using these three variables, we explain signficantly more of the variation in the response variable, Y, than we would using a model with just an intercept, i.e., just that \(Y\) = mean(\(Y\)).
For a multiple regression model, we calculate the F statistic as follows:
\[F = \frac{R^2(n-p-1)}{(1-R^2)p}\]
where…
\(R^2\) = multiple R squared value
\(n\) = number of data points
\(p\) = number of parameters estimated from the data (i.e., the number of \(\beta\) coefficients, not including the intercept)
Second, looking at summary() we see that the \(\beta\) coefficient for each of our predictor variables (including X3) is significant. That is, each predictor is significant even when the effects of the other predictor variables are held constant. Recall that in the simple linear regression, the \(\beta\) coefficient for X3 was not significant.
Third, we can interpret our \(\beta\) coefficients as we did in simple linear regression… for each change of one unit in a particular predictor variable (holding the other predictors constant), our predicted value of the response variable changes \(\beta\) units.
21.4.1 Plotting Effects
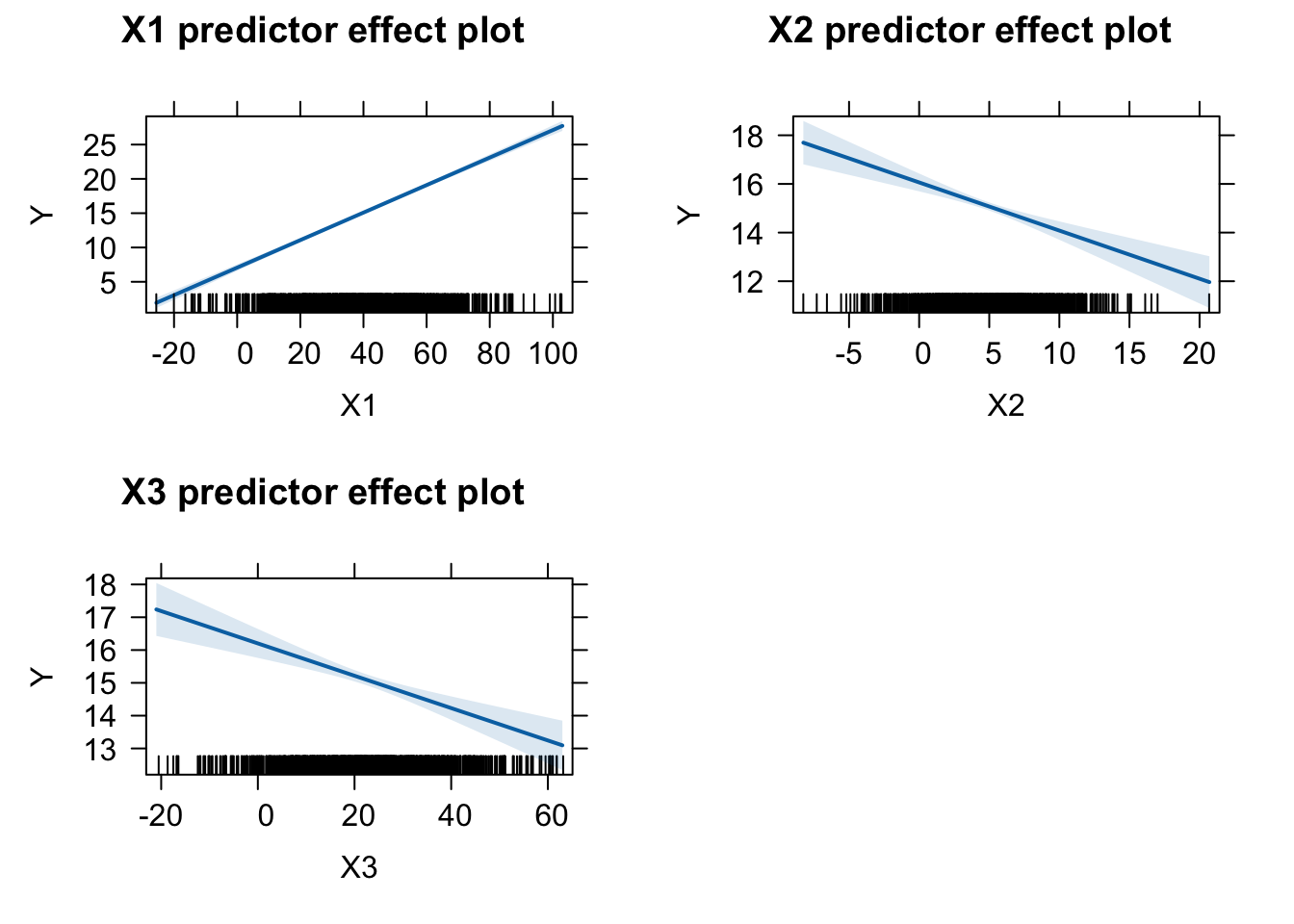
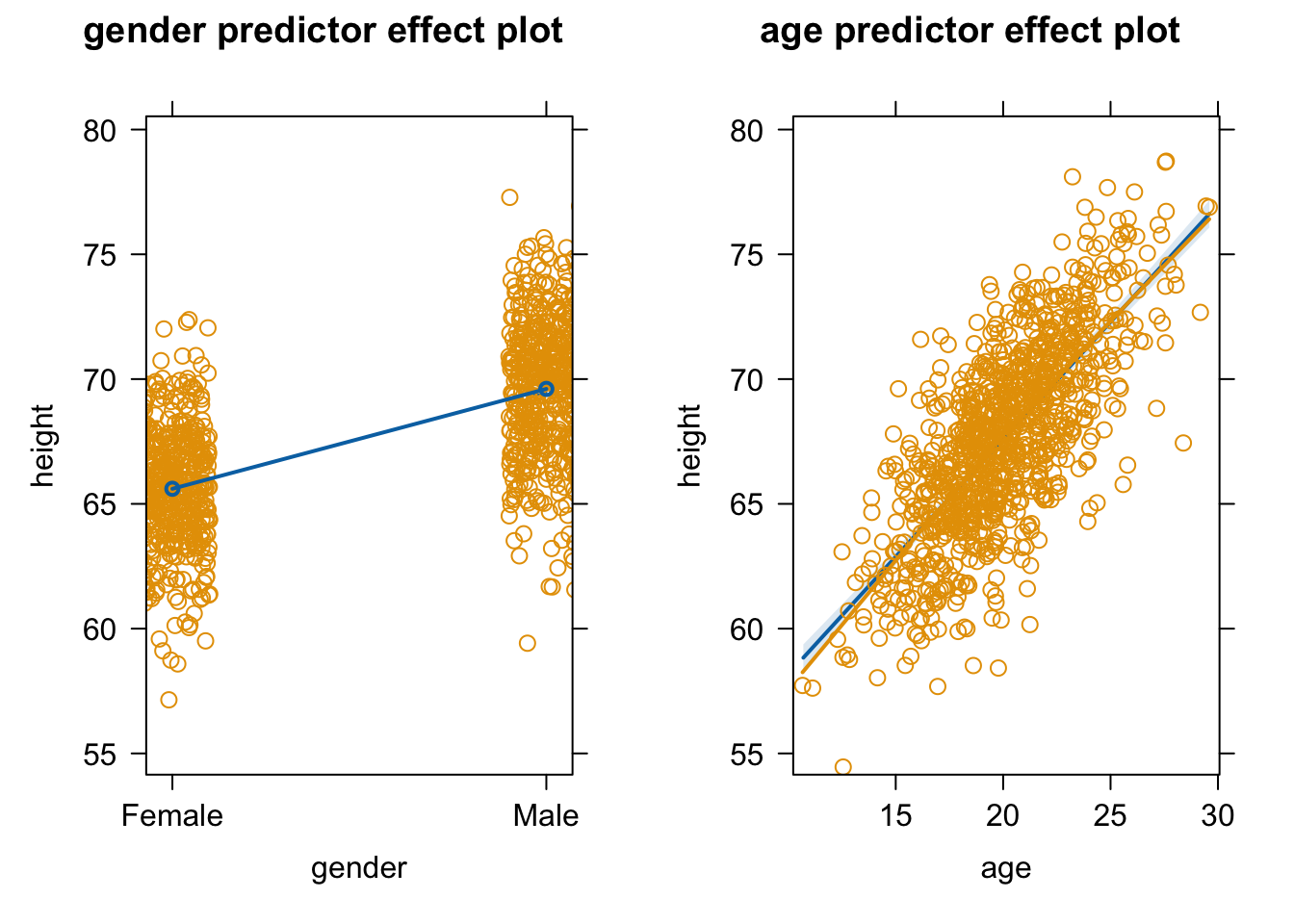
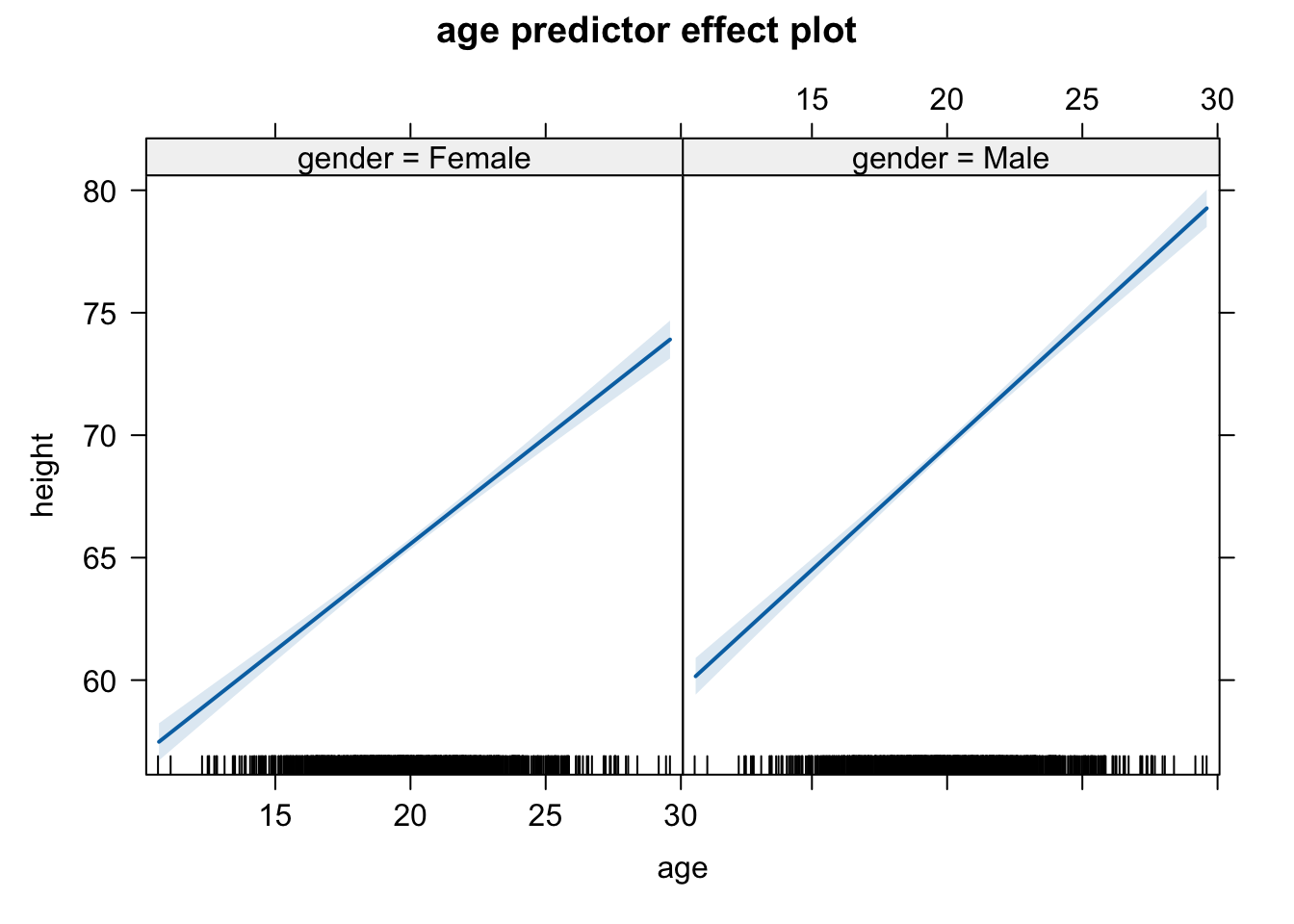
We can use the versatile {effects} package to visualize the results of a variety of model objects, include general and generalized linear models and mixed effects models. The function predictorEffects() with no arguments will display the linear relationship between the response variable and each predictor.
plot(predictorEffects(m))
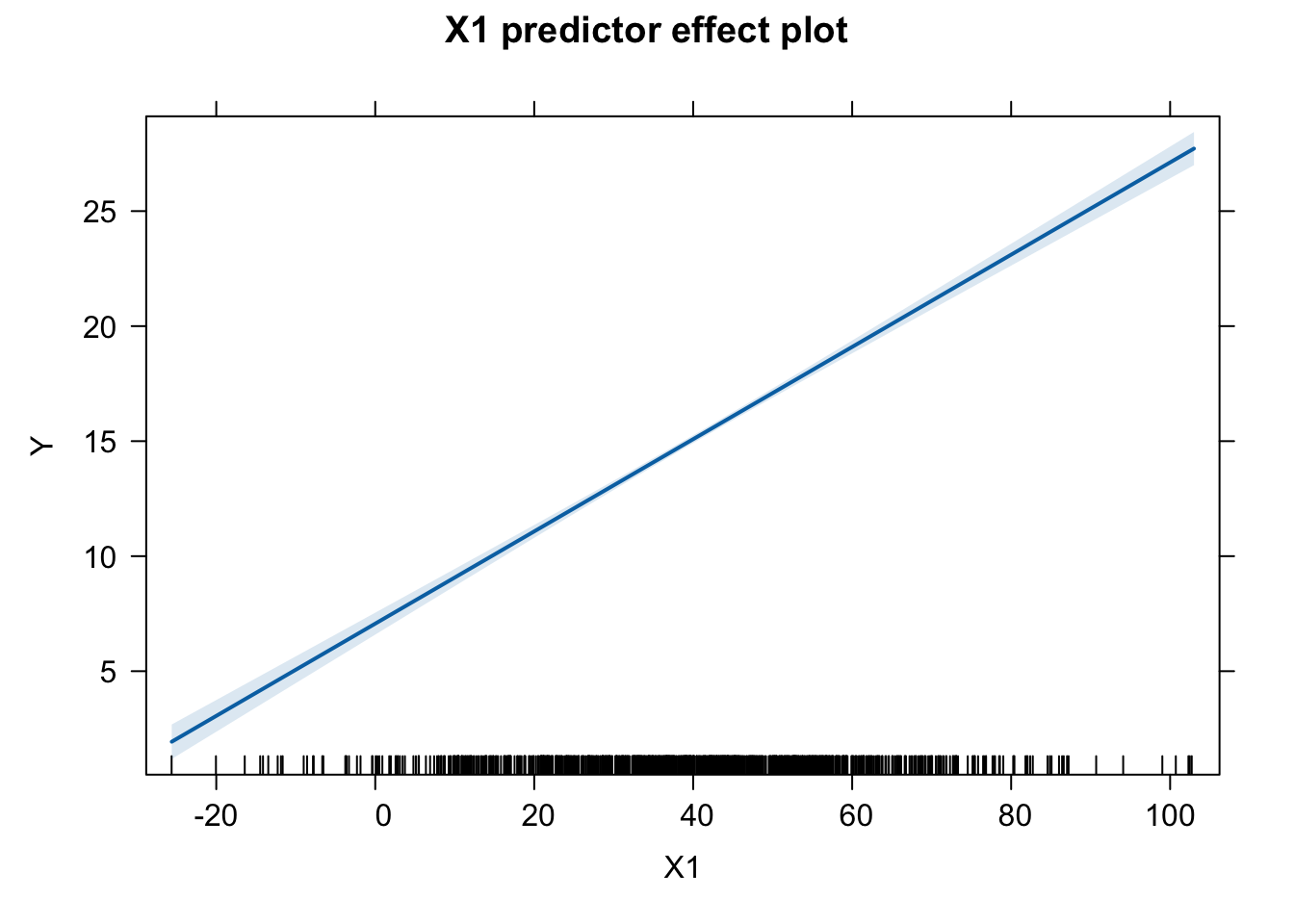
We can also specify particular predictors we wish to look at by adding the “predictors = ~” argument…
plot(predictorEffects(m, predictors =~X1))
Specifying the argument “partial.residuals = TRUE” returns the same plots as above, plus the values of the residuals after subtracting off the contribution from all other explanatory variables as well as a loess smoothed line of best fit through the residuals. Such plots are useful for detecting, for example, nonlinear relationships or interactions between predictors that are not obvious from looking at the original data.
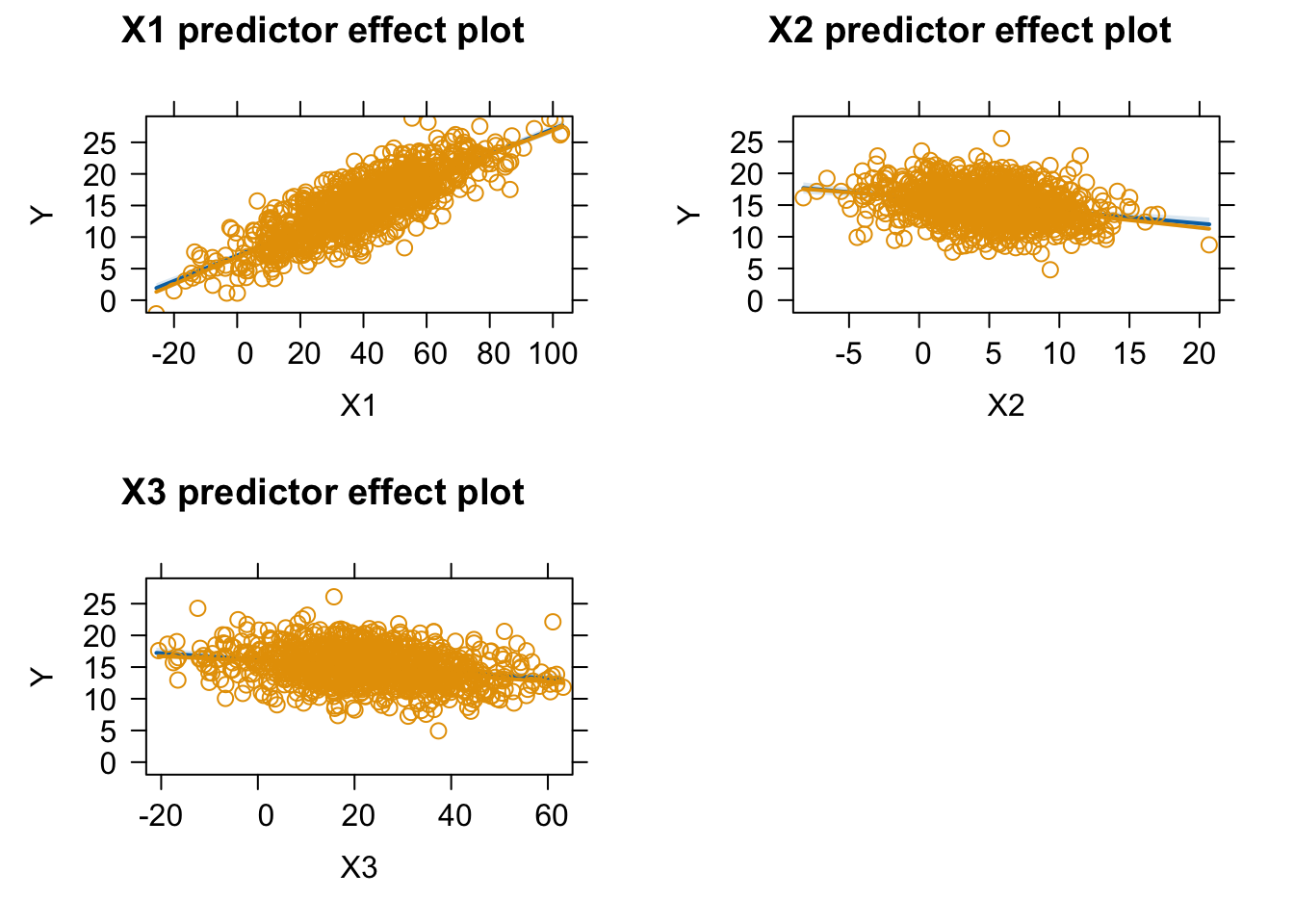
The {ggeffects} package allows us to similarly predict and plot marginal effects from a model object. The predict_response() function takes a model object and one or more focal terms and returns the predicted values for the response variable across values of the focal term, along a specified margin (“mean_reference” by default) for the nonfocal terms. These can then be plotted with the plot() function.
plot(p, show_data =TRUE, jitter =0.1) # superimpose original data
plot(p, show_residuals =TRUE, show_residuals_line =TRUE, jitter =0.1) # superimpose residuals and loess smoothed line of best fit
## `geom_smooth()` using formula = 'y ~ x'
detach(package:ggeffects)
CHALLENGE
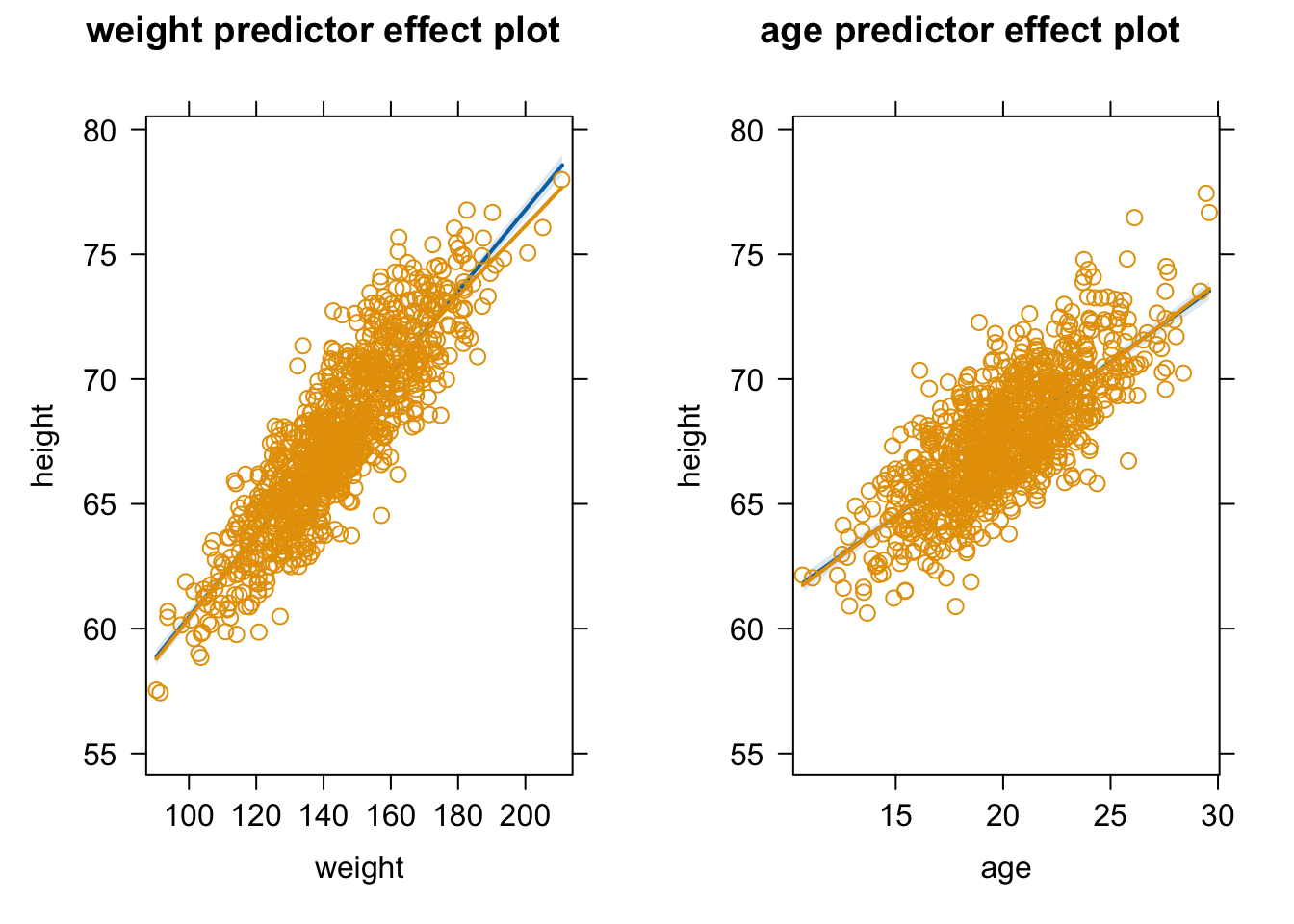
Load up the “zombies.csv” dataset with the characteristics of zombie apocalypse survivors again and run a linear model of height as a function of both weight and age. Is the overall model significant? Are both predictor variables significant when the other is controlled for? Make effects plots for each variable, plotting the partial residuals and the loess smoothed relationship between the residuals and each predictor.
Show Code
f <-"https://raw.githubusercontent.com/difiore/ada-datasets/main/zombies.csv"d <-read_csv(f, col_names =TRUE)
## Rows: 1000 Columns: 10
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (4): first_name, last_name, gender, major
## dbl (6): id, height, weight, zombies_killed, years_of_education, age
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Show Code
head(d)
Show Output
## # A tibble: 6 × 10
## id first_name last_name gender height weight zombies_killed
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 1 Sarah Little Female 62.9 132. 2
## 2 2 Mark Duncan Male 67.8 146. 5
## 3 3 Brandon Perez Male 72.1 153. 1
## 4 4 Roger Coleman Male 66.8 130. 5
## 5 5 Tammy Powell Female 64.7 132. 4
## 6 6 Anthony Green Male 71.2 153. 1
## # ℹ 3 more variables: years_of_education <dbl>, major <chr>, age <dbl>
Show Code
m <-lm(data = d, height ~ weight + age)summary(m)
Show Output
##
## Call:
## lm(formula = height ~ weight + age, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.2278 -1.1782 -0.0574 1.1566 5.4117
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 31.763388 0.470797 67.47 <2e-16 ***
## weight 0.163107 0.002976 54.80 <2e-16 ***
## age 0.618270 0.018471 33.47 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.64 on 997 degrees of freedom
## Multiple R-squared: 0.8555, Adjusted R-squared: 0.8553
## F-statistic: 2952 on 2 and 997 DF, p-value: < 2.2e-16
Continous Response Variable with both Continuous and Categorical Predictors
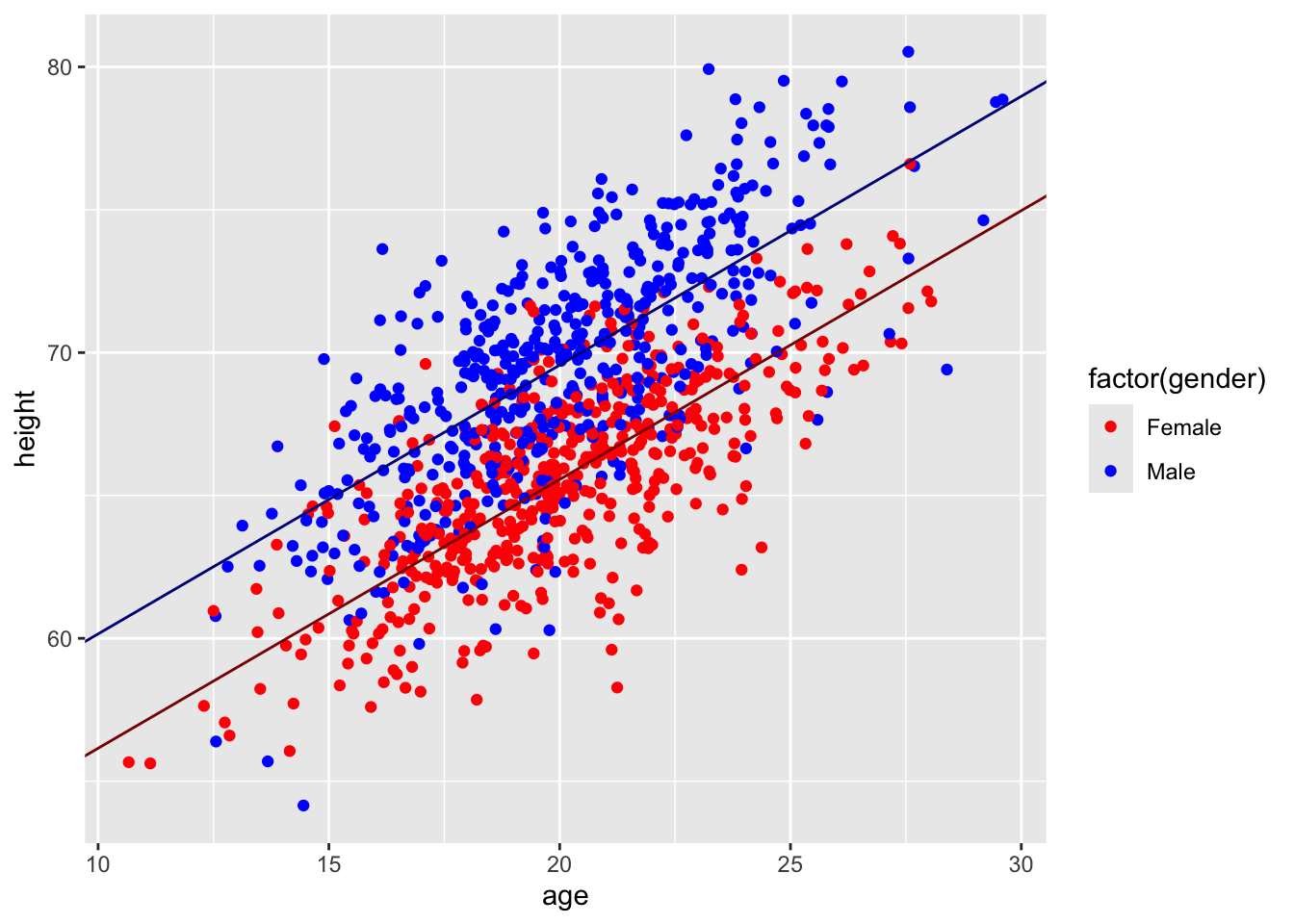
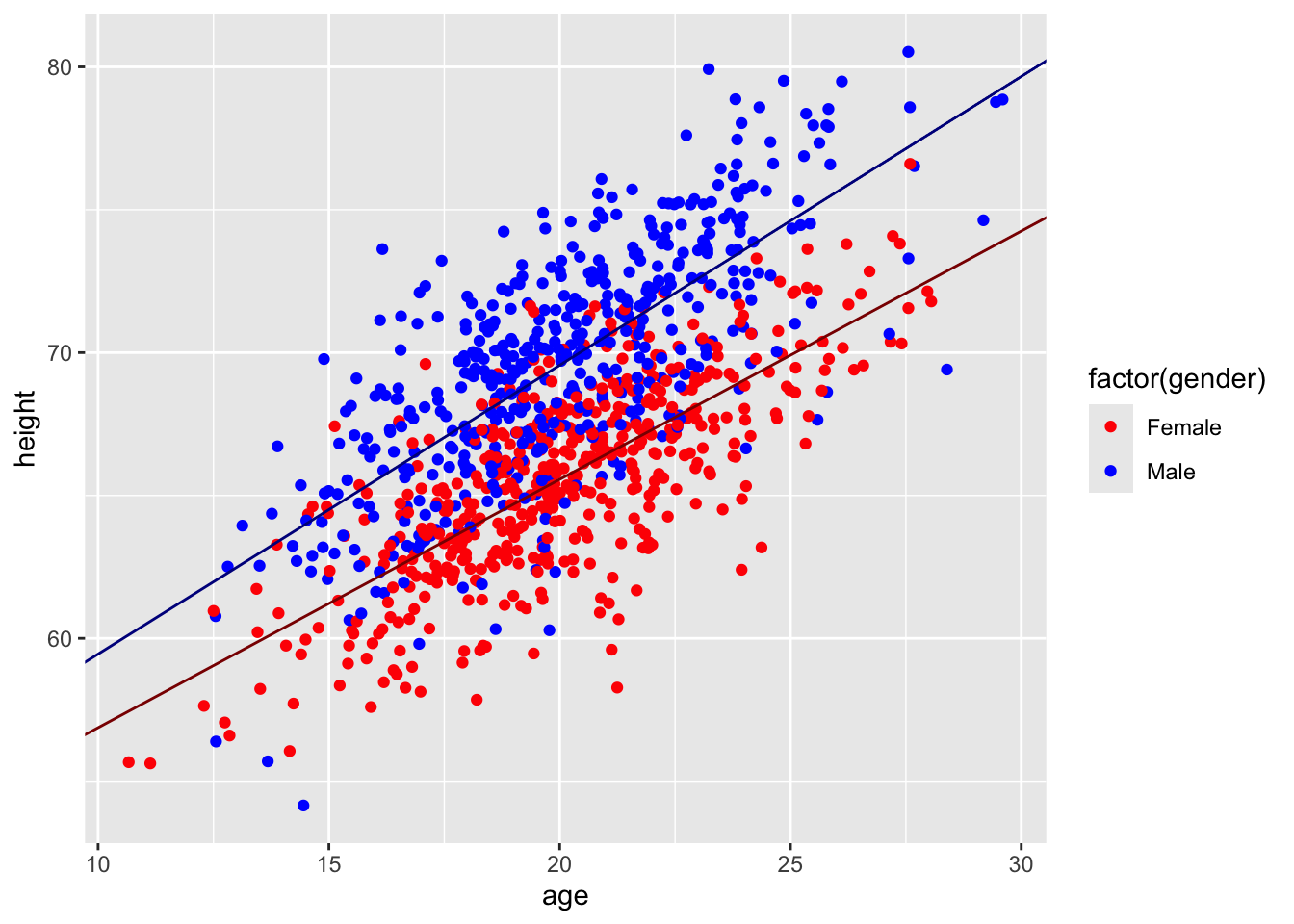
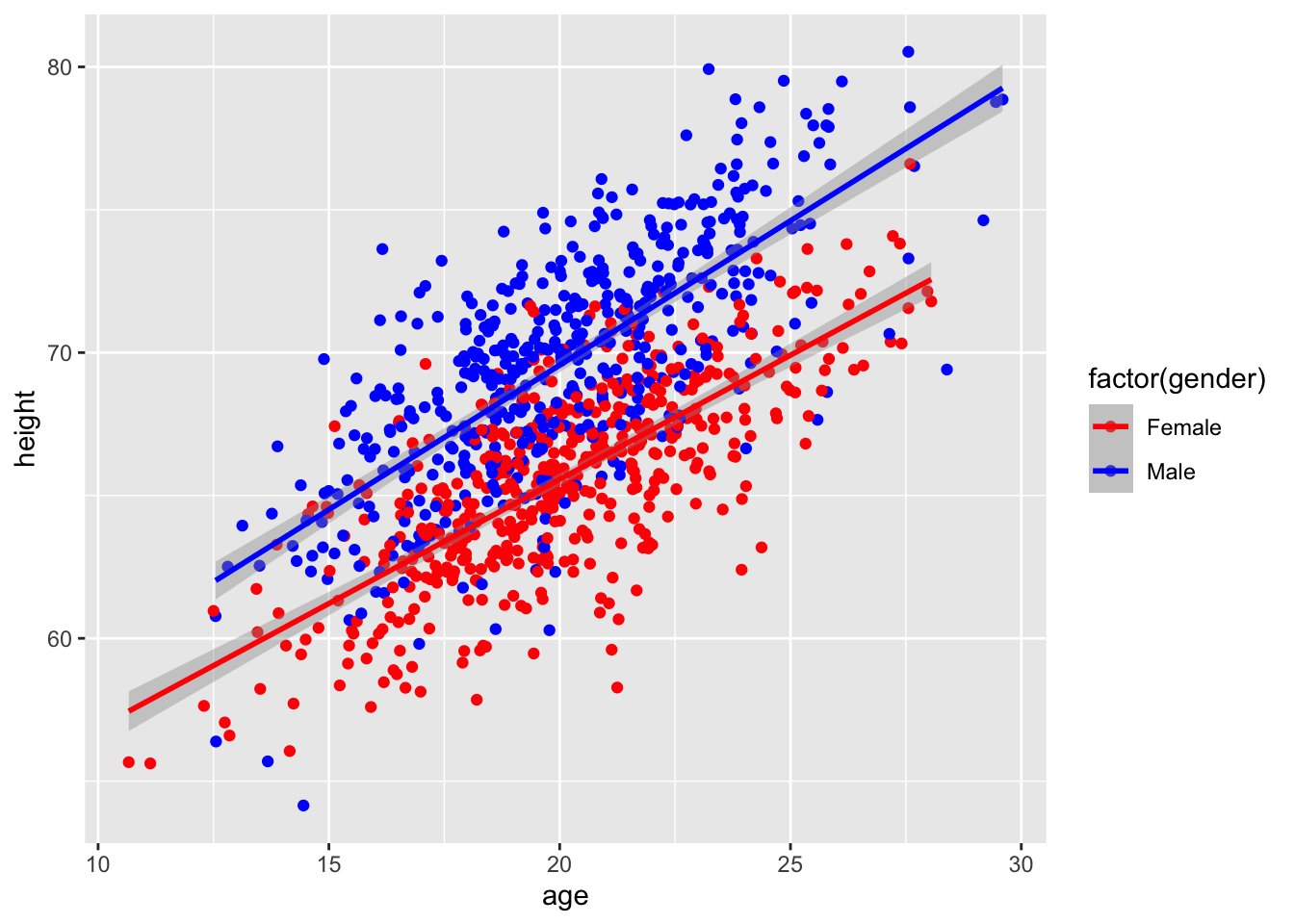
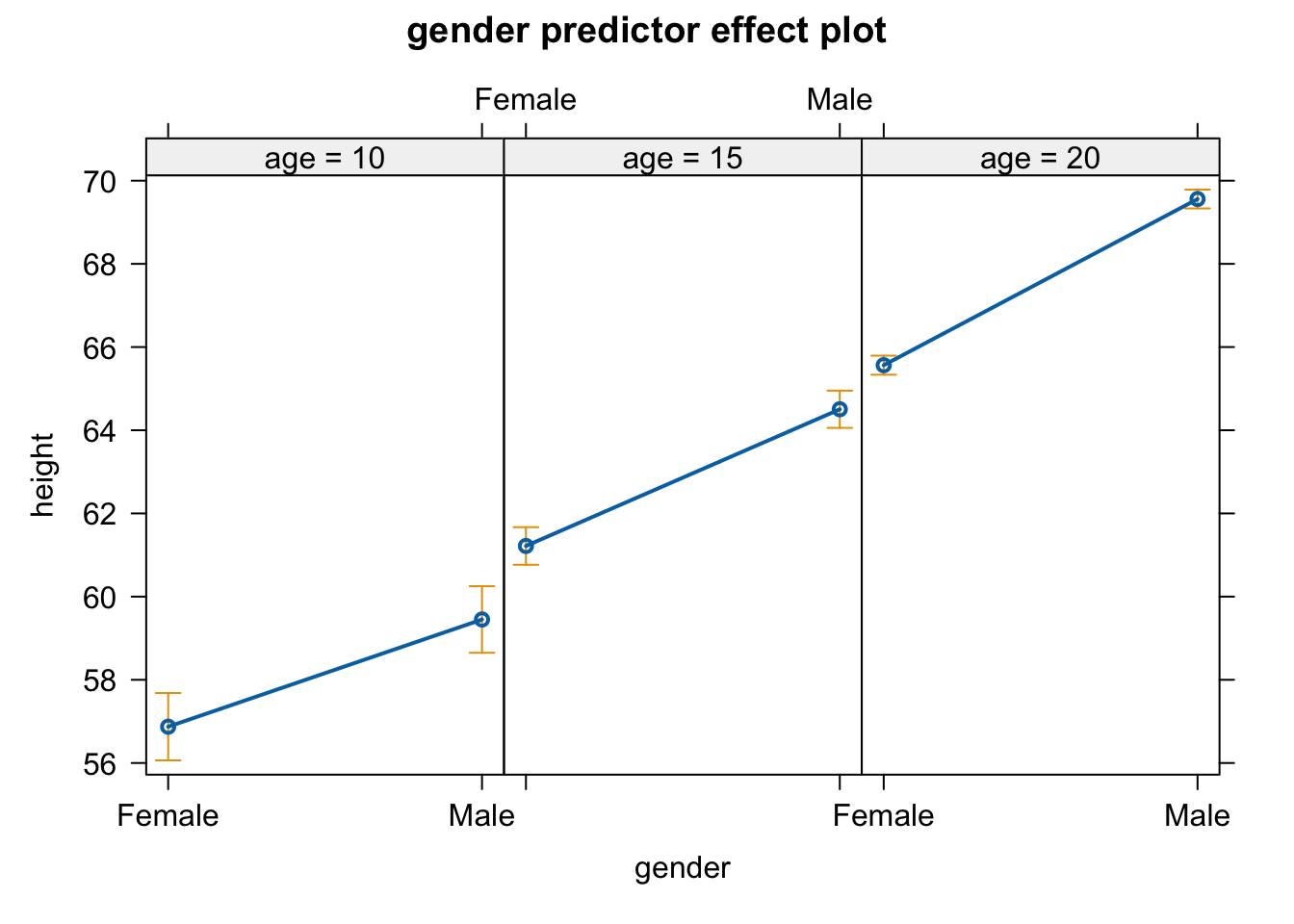
We can use the same linear modeling approach to do analysis of covariance, or ANCOVA, where we have a continuous response variable and a combination of continuous and categorical predictor variables. Let’s return to the “zombies.csv” dataset and now include one continuous and one categorical variable in our model… we want to predict height as a function of age (a continuous variable) and gender (a categorical variable), and we want to use Type II regression (because we have an unbalanced design). What is our model formula?
Here, the additional 4.00224 added to the intercept term is the coefficient associated with genderMale
p <-ggplot(data = d, aes(x = age, y = height)) +geom_point(aes(color =factor(gender))) +scale_color_manual(values =c("red", "blue"))p <- p +geom_abline(slope = m$coefficients[3],intercept = m$coefficients[1],color ="darkred")p <- p +geom_abline(slope = m$coefficients[3],intercept = m$coefficients[1] + m$coefficients[2],color ="darkblue")p
Note that this model is based on all of the data collectively… we are not doing separate linear models for males and females, which could result in different intercepts and slopes for each sex… rather, we are modeling both sexes as having the same slope but different intercepts. This is what is known as a “parallel slopes” model. Below, we will explore a model where we posit an interaction between age and sex, which would require estimation of four separate parameters (i.e., both a slope and an intercept for males and females rather than, as above, only different intercepts for males and females but the same slope for each sex).
Using the confint() function on our ANCOVA model results reveals the confidence intervals for each of the coefficients in our multiple regression, just as it did for simple regression.
When we have more than one explanatory variable in a regression model, we need to be concerned about possible high inter-correlations those variables. One way to characterize the amount of multicollinearity is by examining the variance inflation factor, or VIF, for each variable. Mathematically, the VIF for a predictor variable i is calculated as:
\[\frac{1}{1-R_i^2}\] where \(R_i^2\) is the R-squared value for the regression of variable i on all other predictors. A high VIF indicates that the predictor is highly collinear with other predictors in the model. As a rule of thumb, a VIF value that exceeds ~5 indicates a problematic amount of multicollinearity. The function vif() from the {car} package provides one way to calculate VIFs.
Below, we set up a new model with three predictors, weight, age, and gender, and calculate VIFs:
m <-lm(height ~ weight + age + gender, data = d)summary(m)
##
## Call:
## lm(formula = height ~ weight + age + gender, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.6235 -1.0082 0.0141 0.9845 4.6444
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 33.309791 0.437855 76.08 <2e-16 ***
## weight 0.140542 0.003083 45.59 <2e-16 ***
## age 0.662485 0.016953 39.08 <2e-16 ***
## genderMale 1.609671 0.107436 14.98 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.482 on 996 degrees of freedom
## Multiple R-squared: 0.8821, Adjusted R-squared: 0.8818
## F-statistic: 2484 on 3 and 996 DF, p-value: < 2.2e-16
vif(m)
## weight age gender
## 1.463629 1.149158 1.313461
We can also calculate VIFs manually, by running models that regress each individual predictor on all of the others…
w <-lm(weight ~ gender + age, data = d)rsq_w <-summary(w)$r.square(vif_w <-1/ (1- rsq_w))
## [1] 1.463629
a <-lm(age ~ gender + weight, data = d)rsq_a <-summary(a)$r.square(vif_a <-1/ (1- rsq_a))
## [1] 1.149158
# for a categorical predictor variable, we can coerce it to numeric to use it as a response variableg <-lm(as.numeric(gender) ~ age + weight, data = d)rsq_g <-summary(g)$r.square(vif_g <-1/ (1- rsq_g))
## [1] 1.313461
21.7 Confidence and Prediction Intervals
One common reason for fitting a regression model is to then use that model to predict the value of the response variable under particular combinations of values of predictor variables, i.e., to predict the values of new observations. We can think of the Y value predicted by the regression model (\(\hat{y}\)) as a point estimate of the response variable given particular value(s) of the predictor variable(s). This point estimate is associated with some uncertainty, which we can characterize in terms of either confidence intervals or prediction intervals around each the estimate. CIs represent uncertainty about the mean value of the response variable for a given (combination of) predictor value(s), while PIs represent our uncertainty about actual new predicted values of the response variable at those predictor value(s).
The predict() allows us to determine these intervals for individual responses for a given combination of predictor variables. predict() takes as arguments a model object, new values for the predictor(s) to be plugged into the model, an interval type (“confidence” or “prediction”), and a confidence level (e.g., “0.95”).
CHALLENGE
Let’s return to our model of height as a function of age and gender:
m <-lm(height ~ age + gender, data = d)
What is the predicted mean height, in inches, for 29-year old males who have survived the zombie apocalypse? What is the 95% confidence interval around this predicted mean height?
Show Code
ci <-predict(m,newdata =data.frame(age =29, gender ="Male"),interval ="confidence", level =0.95)ci
Show Output
## fit lwr upr
## 1 78.03124 77.49345 78.56903
What is the 95% prediction interval for the individual heights of 29-year old male zombie apocalypse survivors?
Show Code
pi <-predict(m,newdata =data.frame(age =29, gender ="Male"),interval ="prediction", level =0.95)pi
Show Output
## fit lwr upr
## 1 78.03124 72.89597 83.16651
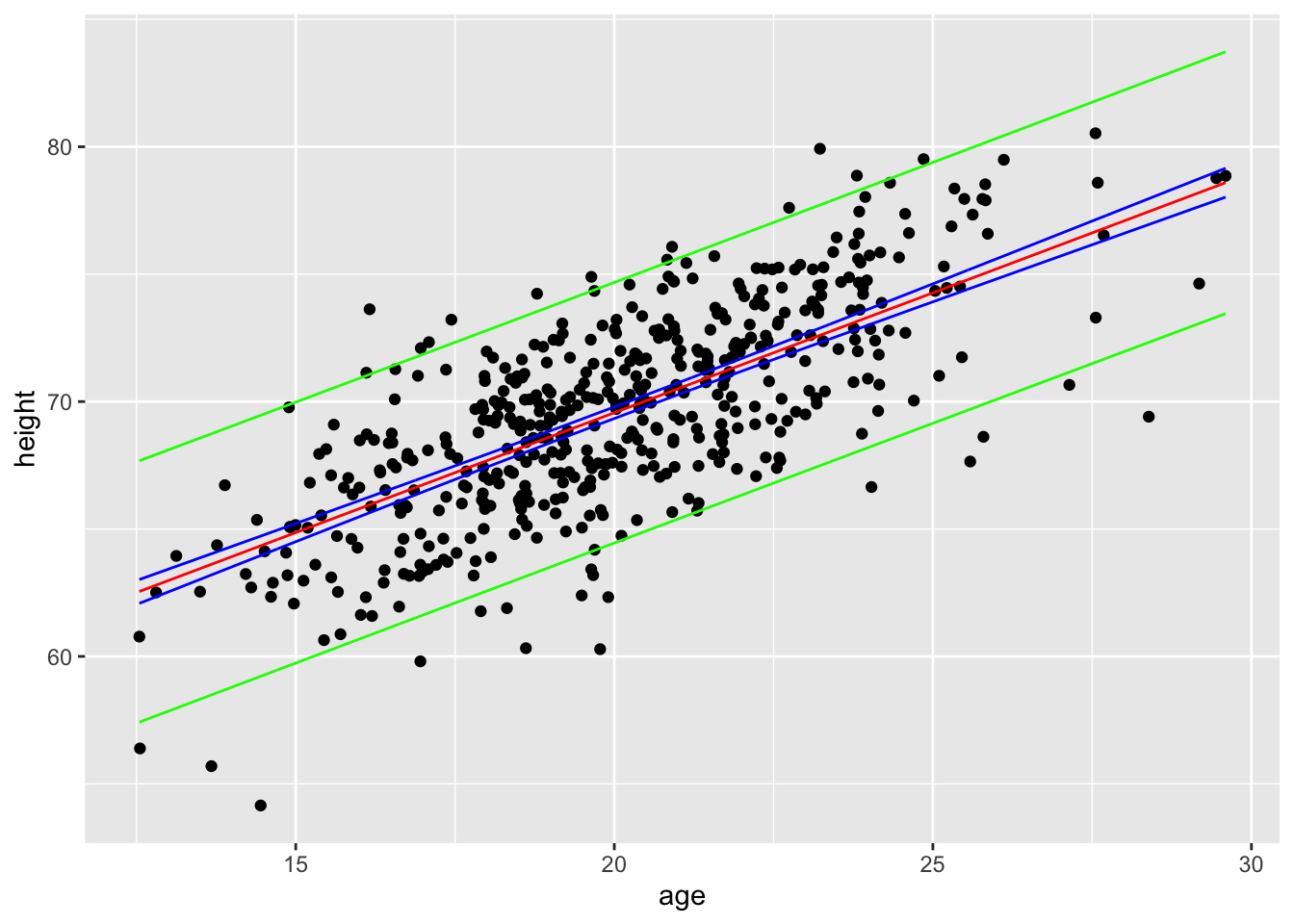
In general, the width of a confidence interval for \(\hat{y}\) increases as the value of our predictor variables moves away from the center of their distribution. Also, although both are intervals are centered at \(\hat{y}\), the predicted mean value of the response variable for the given (combination of) predictor(s), the prediction interval is invariably wider than the confidence interval. This makes intuitive sense, since the prediction interval encapsulates the possibility for individual values of Y to fluctuate away from the predicted mean value, while the confidence interval describes uncertainty in estimates of the predicted mean value. That is, the estimate of the mean of a variable is expected to be less uncertain than estimates of individual variable values, because the mean is already a statistic that summarizes a set of values.
We can see this by generating CIs and PIs for a range of data using the predict() function. Below, we pass predict() a new set of 1000 values ranging from the minimum to the maximum male age in our original data set…
males <- d |>filter(gender =="Male")new_x <-seq(from =min(males$age), to =max(males$age), length.out =1000)ci <-predict( m,newdata =data.frame(age = new_x, gender ="Male"),interval ="confidence", level =0.95)ci <-tibble(x = new_x, as_tibble(ci))pi <-predict( m,newdata =data.frame(age = new_x, gender ="Male"),interval ="prediction",level =0.95)pi <-as_tibble(pi)pi <-tibble(x = new_x, as_tibble(pi))p <-ggplot(data = d |>filter(gender =="Male"),aes(x = age, y = height)) +geom_point() +geom_line(data = ci, aes(x = x, y = fit), color ="red") +geom_line(data = ci, aes(x = x, y = lwr), color ="blue") +geom_line(data = ci, aes(x = x, y = upr), color ="blue") +geom_line(data = pi, aes(x = x, y = lwr), color ="green") +geom_line(data = pi, aes(x = x, y = upr), color ="green")p
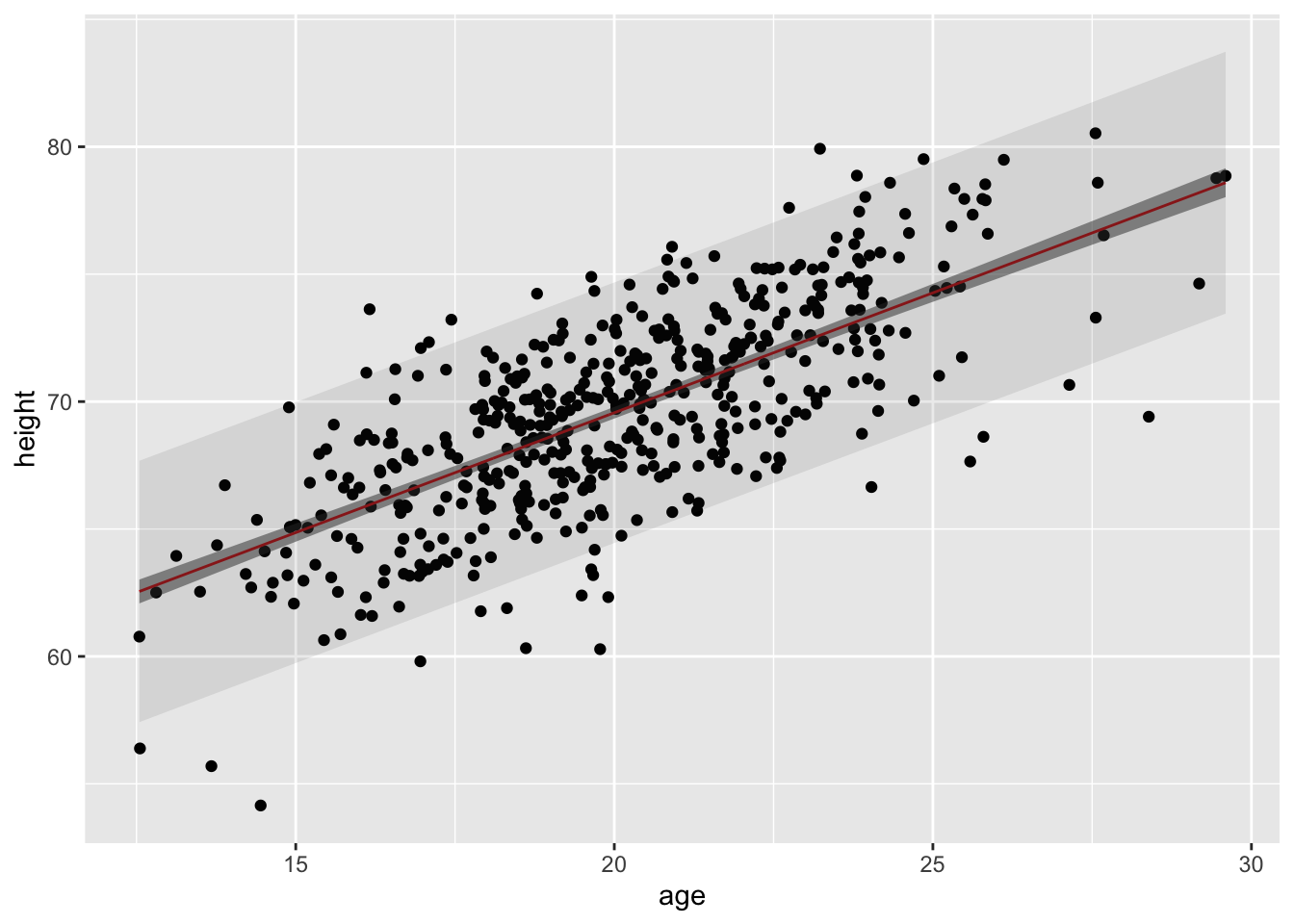
An easier, alternative way to generate CIs and PIs for across a range of predictor values iswith the augment() function from {broom}, as it returns a “tibble” with fitted values and interval limits appended to the original data frame.
ci <-augment( m,data = d,interval =c("confidence"))pi <-augment( m,data = d,interval =c("prediction"))p <-ggplot(data = ci |>filter(gender =="Male"), aes(x = age, y = height)) +geom_point() +geom_line(aes(x = age, y = .fitted), color ="red") +geom_ribbon(aes(x = age, ymin = .lower, ymax = .upper), alpha =0.5) +geom_ribbon(data = pi |>filter(gender =="Male"), aes(x = age, ymin = .lower, ymax = .upper), alpha =0.1)p
21.8 Interactions Between Predictors
So far, we have only considered the joint main effects of multiple predictors on a response variable, but often there are interactive effects between our predictors. An interactive effect is an additional change in the response that occurs because of particular combinations of predictors or because the relationship of one continuous variable to a response is contingent on a particular level of a categorical variable. We explored the former case a bit when we looked at ANOVAs involving two discrete predictors. Now, we’ll consider the latter case… is there an interactive effect of sex AND age on height in our population of zombie apocalypse survivors?
Using formula notation, it is easy for us to consider interactions between predictors. The colon (:) operator allows us to specify particular interactions we want to consider. We can also use the asterisk (*) operator to specify a full model, i.e., all single terms factors and all their interactions.
What are the formula and results for a linear model of height as a function of age and sex plus the interaction of age and sex?
Show Code
m <-lm(data = d, height ~ age + gender + age:gender)summary(m)
Show Output
##
## Call:
## lm(formula = height ~ age + gender + age:gender, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -9.7985 -1.6973 0.1189 1.7662 7.9473
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 48.18107 0.79839 60.348 <2e-16 ***
## age 0.86913 0.03941 22.053 <2e-16 ***
## genderMale 1.15975 1.12247 1.033 0.3018
## age:genderMale 0.14179 0.05539 2.560 0.0106 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.595 on 996 degrees of freedom
## Multiple R-squared: 0.6385, Adjusted R-squared: 0.6374
## F-statistic: 586.4 on 3 and 996 DF, p-value: < 2.2e-16
Show Code
# orm <-lm(data = d, height ~ age * gender)summary(m)
Show Output
##
## Call:
## lm(formula = height ~ age * gender, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -9.7985 -1.6973 0.1189 1.7662 7.9473
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 48.18107 0.79839 60.348 <2e-16 ***
## age 0.86913 0.03941 22.053 <2e-16 ***
## genderMale 1.15975 1.12247 1.033 0.3018
## age:genderMale 0.14179 0.05539 2.560 0.0106 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.595 on 996 degrees of freedom
## Multiple R-squared: 0.6385, Adjusted R-squared: 0.6374
## F-statistic: 586.4 on 3 and 996 DF, p-value: < 2.2e-16
Show Code
coefficients(m)
Show Output
## (Intercept) age genderMale age:genderMale
## 48.1810741 0.8691284 1.1597481 0.1417928
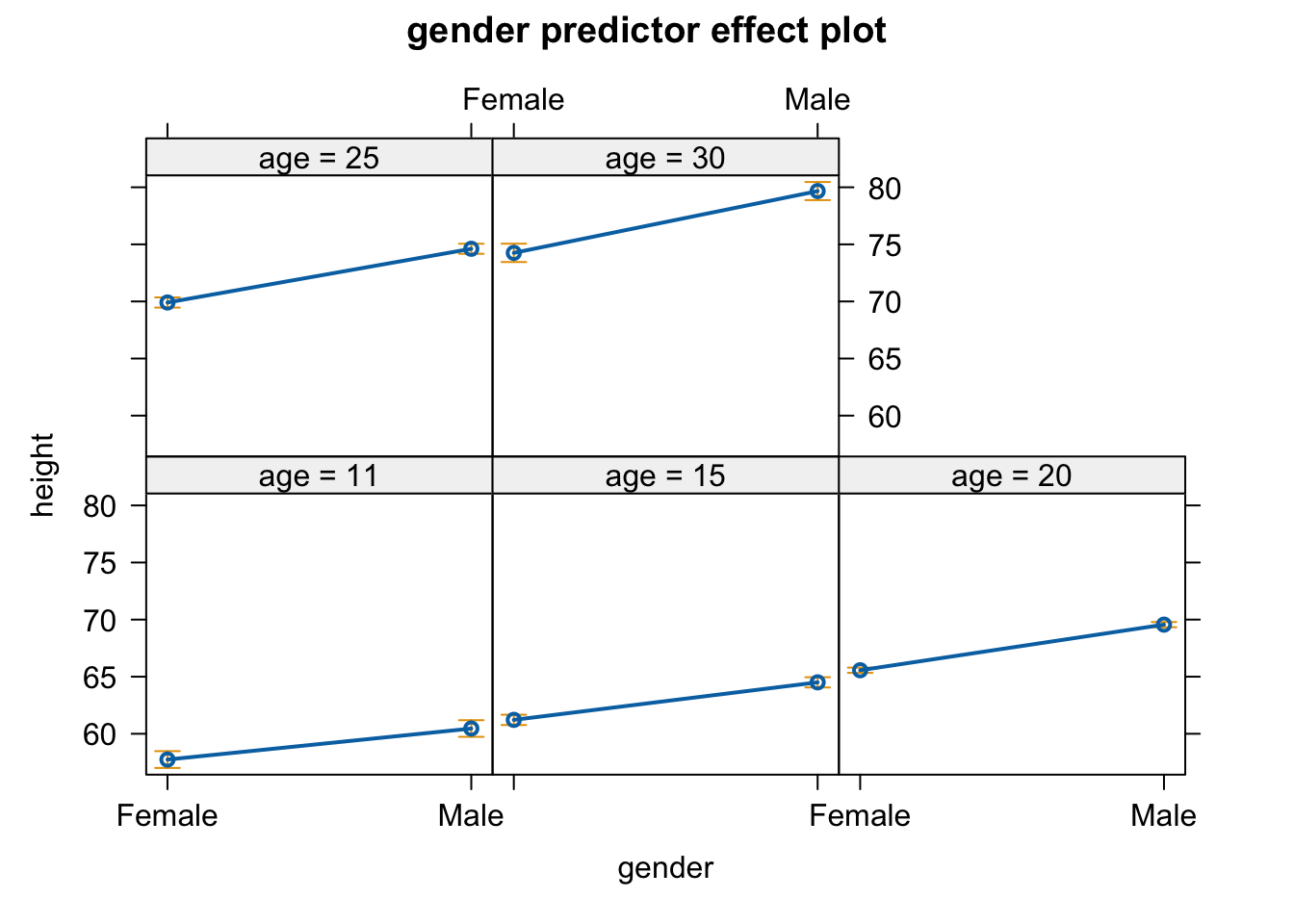
Here, when we allow an interaction, there is no main effect of gender, but there is an interaction effect of gender and age.
The predictorEffects() function from {effects} provides and alternative way to visualize interactions…
plot(predictorEffects(m, predictors =~age))
plot(predictorEffects(m, predictors =~gender))
In the case of gender, the function plots the difference in predicted height of females and males as a set of levels specified by the argument “xlevels=”. The argument can be set to a particular number of levels (which is 5 by default, as in the example above) or it can be passed a list with elements named for the predictors, with either the number of level or a vector of level values added.
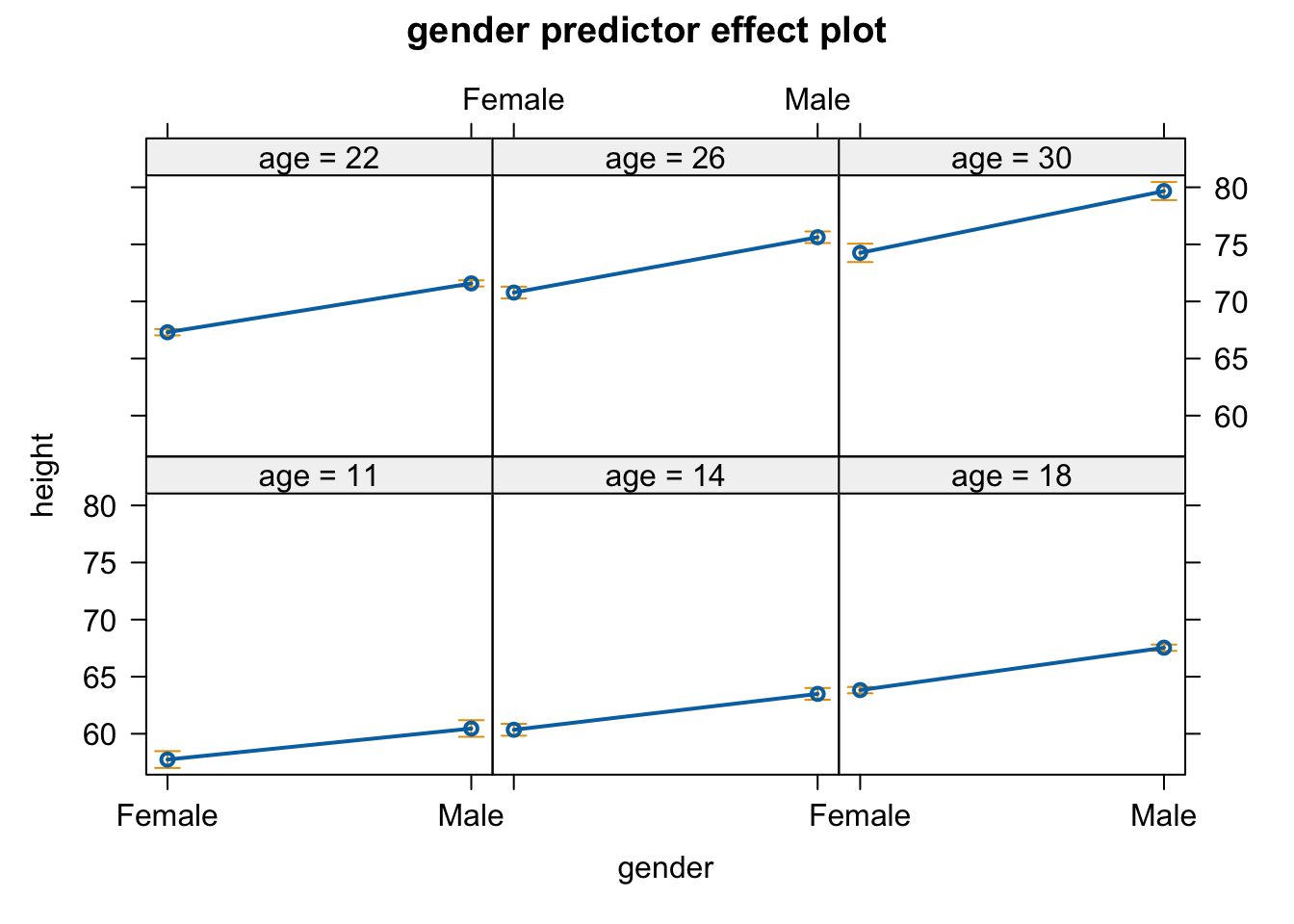
plot(predictorEffects(m, predictors =~gender, xlevels =list(age =6))) # 6 ages, spanning the range of ages in the dataset
plot(predictorEffects(m, predictors =~gender, xlevels =list(age =c(10, 15, 20)))) # 3 ages, specified by the user
CHALLENGE
Load in the “KamilarAndCooper.csv”” dataset we have used previously
Reduce the dataset to the following variables: Family, Brain_Size_Female_Mean, Body_mass_female_mean, MeanGroupSize, DayLength_km, HomeRange_km2, and Move and assign Family to be a factor. Also, rename the brain size, body mass, group size, day length, and home range variables as BrainSize, BodyMass, GroupSize, DayLength, HomeRange
Show Code
f <-"https://raw.githubusercontent.com/difiore/ada-datasets/main/KamilarAndCooperData.csv"d <-read_csv(f, col_names =TRUE)
## Rows: 213 Columns: 45
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (17): Scientific_Name, Superfamily, Family, Genus, Species, Brain_size_R...
## dbl (28): Brain_Size_Species_Mean, Brain_Size_Female_Mean, Body_mass_male_me...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
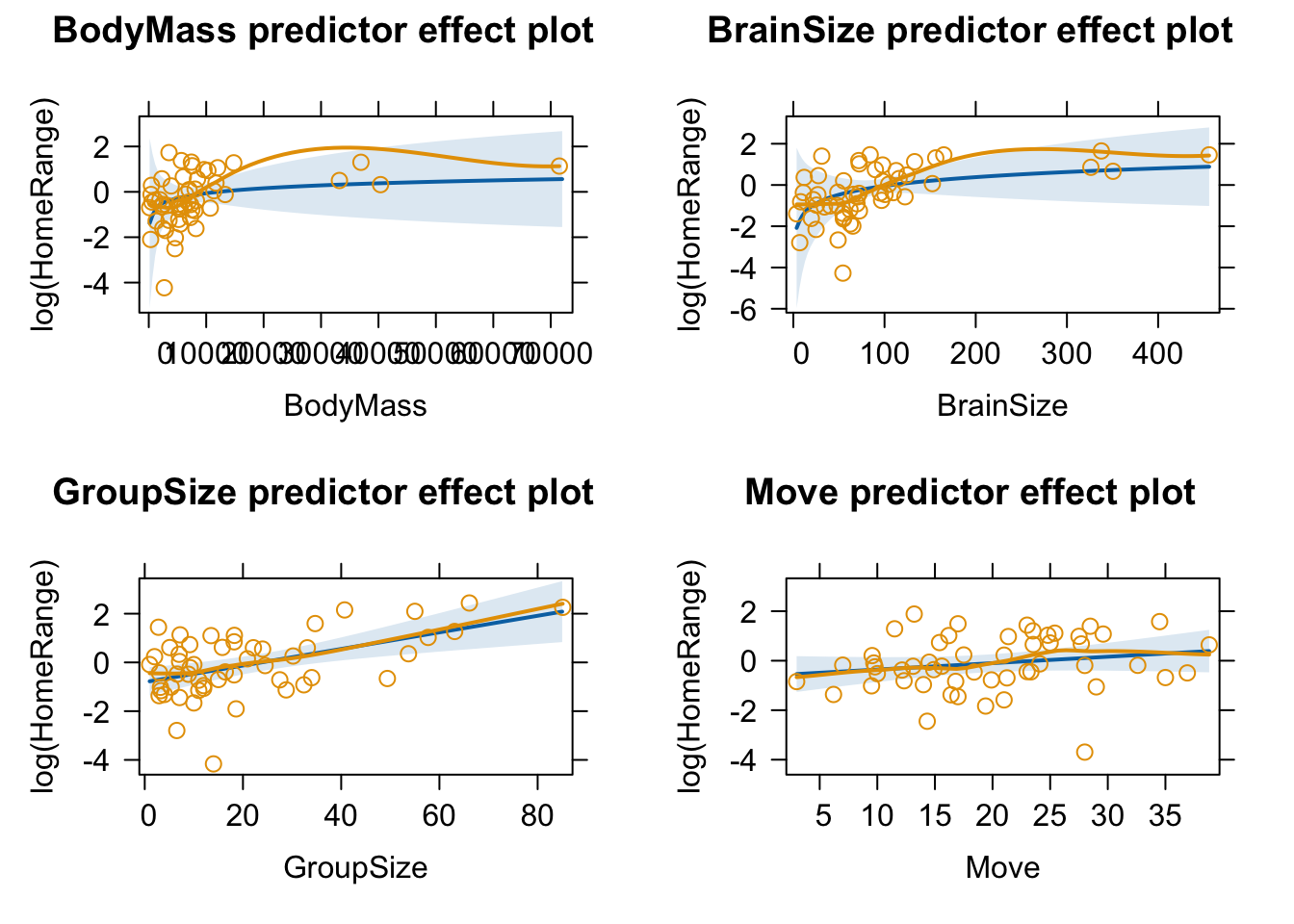
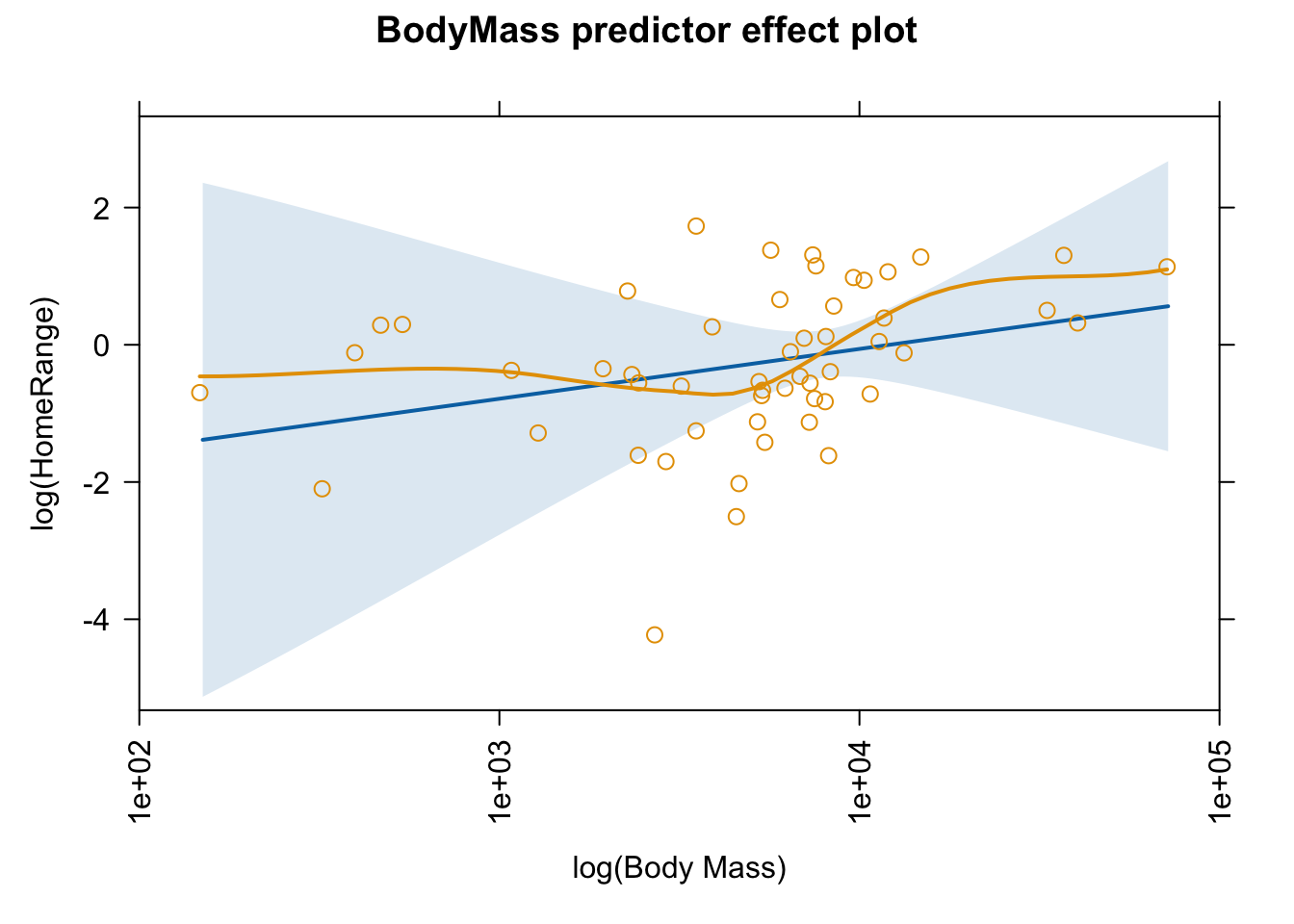
Fit a Model I least squares multiple linear regression model using log(HomeRange) as the response variable and log(BodyMass), log(BrainSize), GroupSize, and Move as predictor variables, and view a model summary.
Look at and interpret the estimated regression coefficients for the fitted model and interpret. Are any of them statistically significant? What can you infer about the relationship between the response and predictors?
Report and interpret the coefficient of determination and the outcome of the omnibus F test.
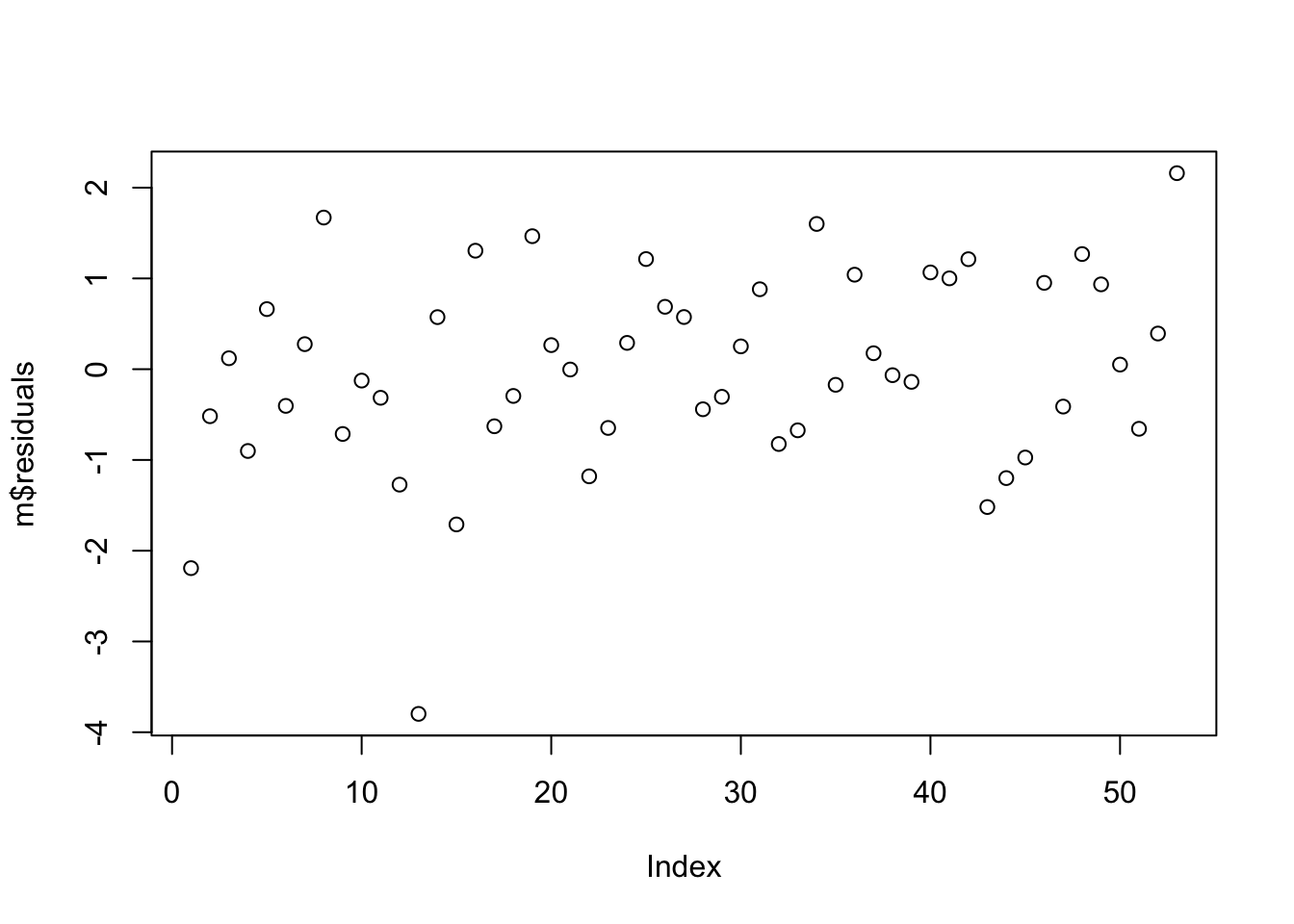
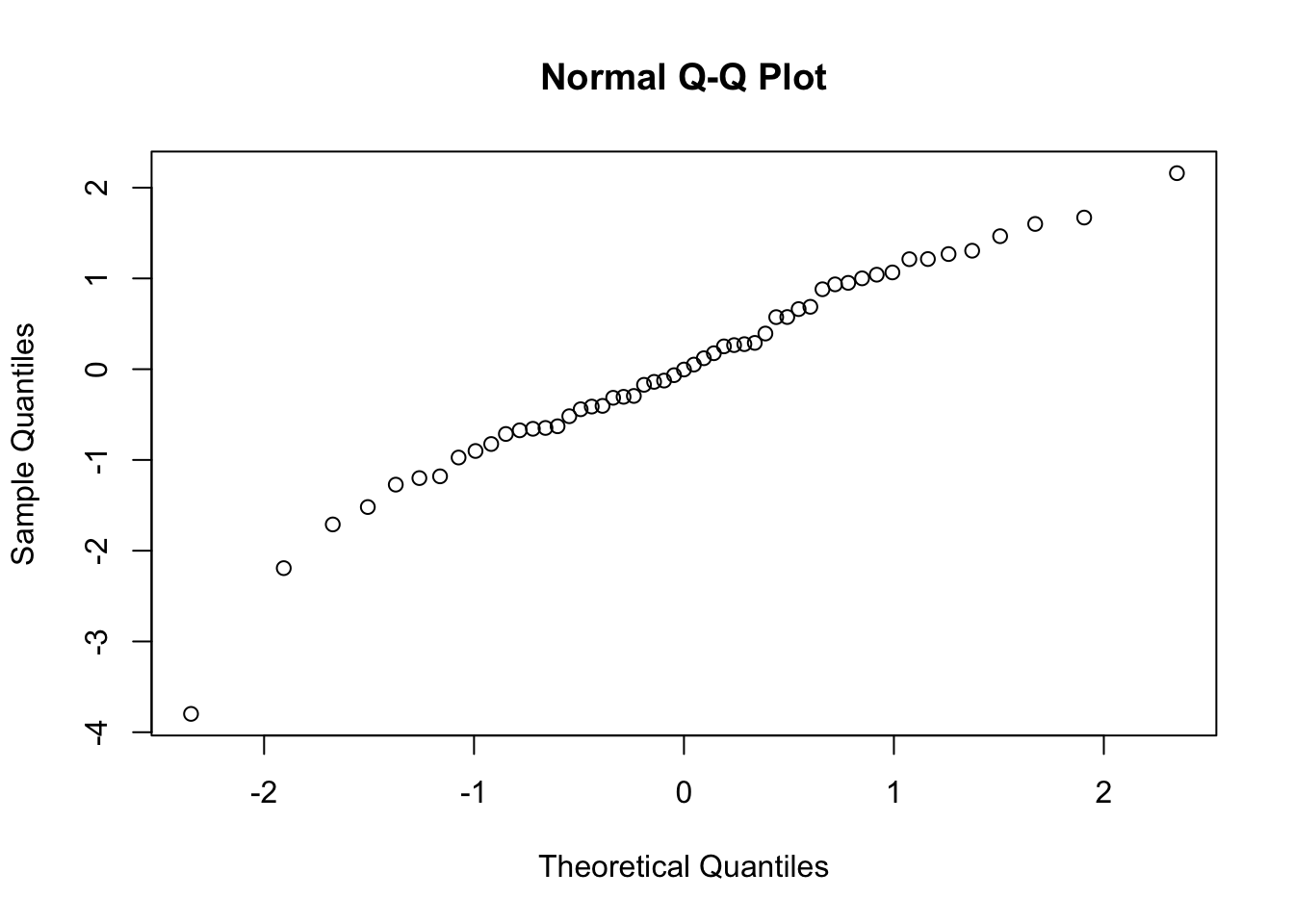
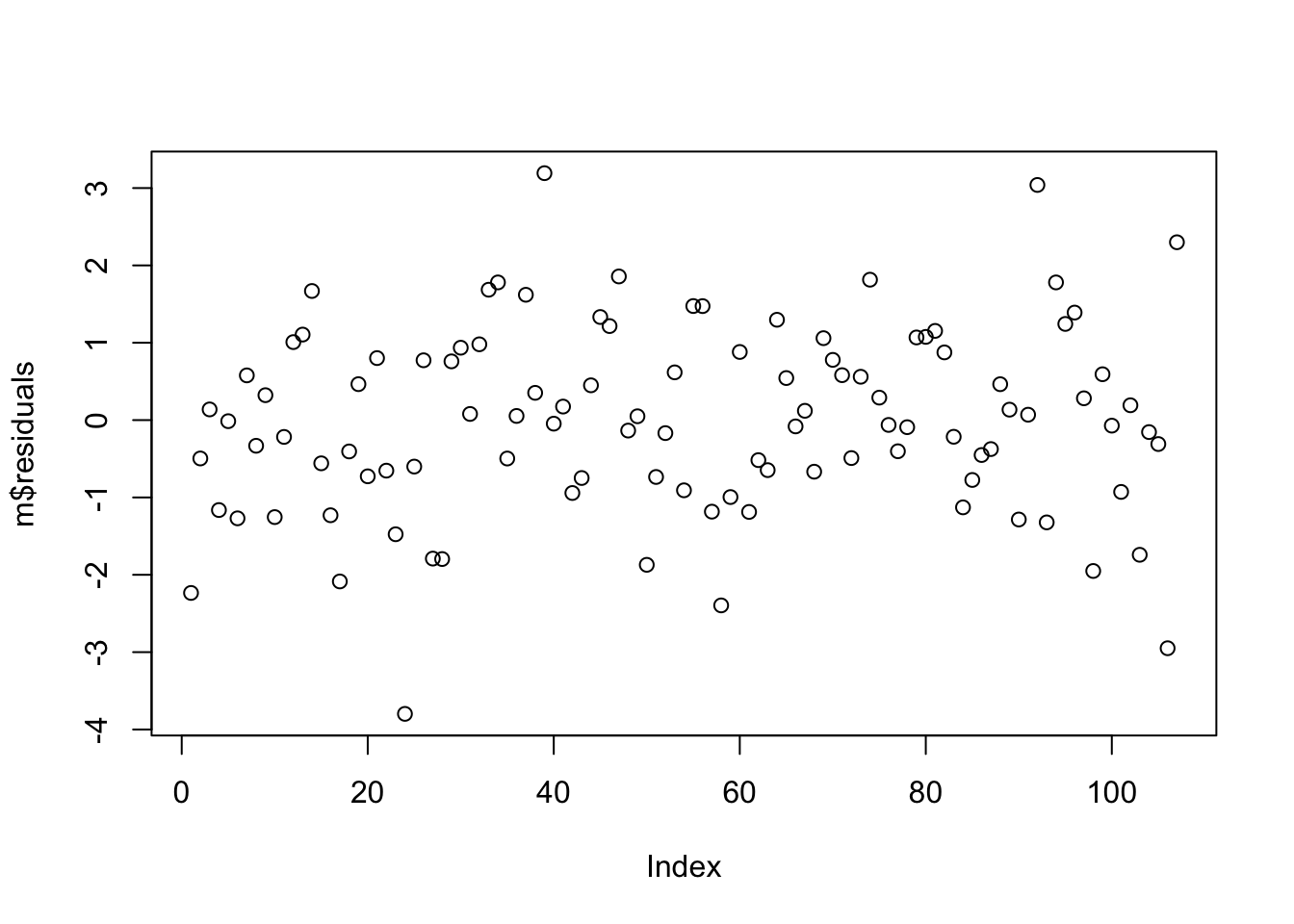
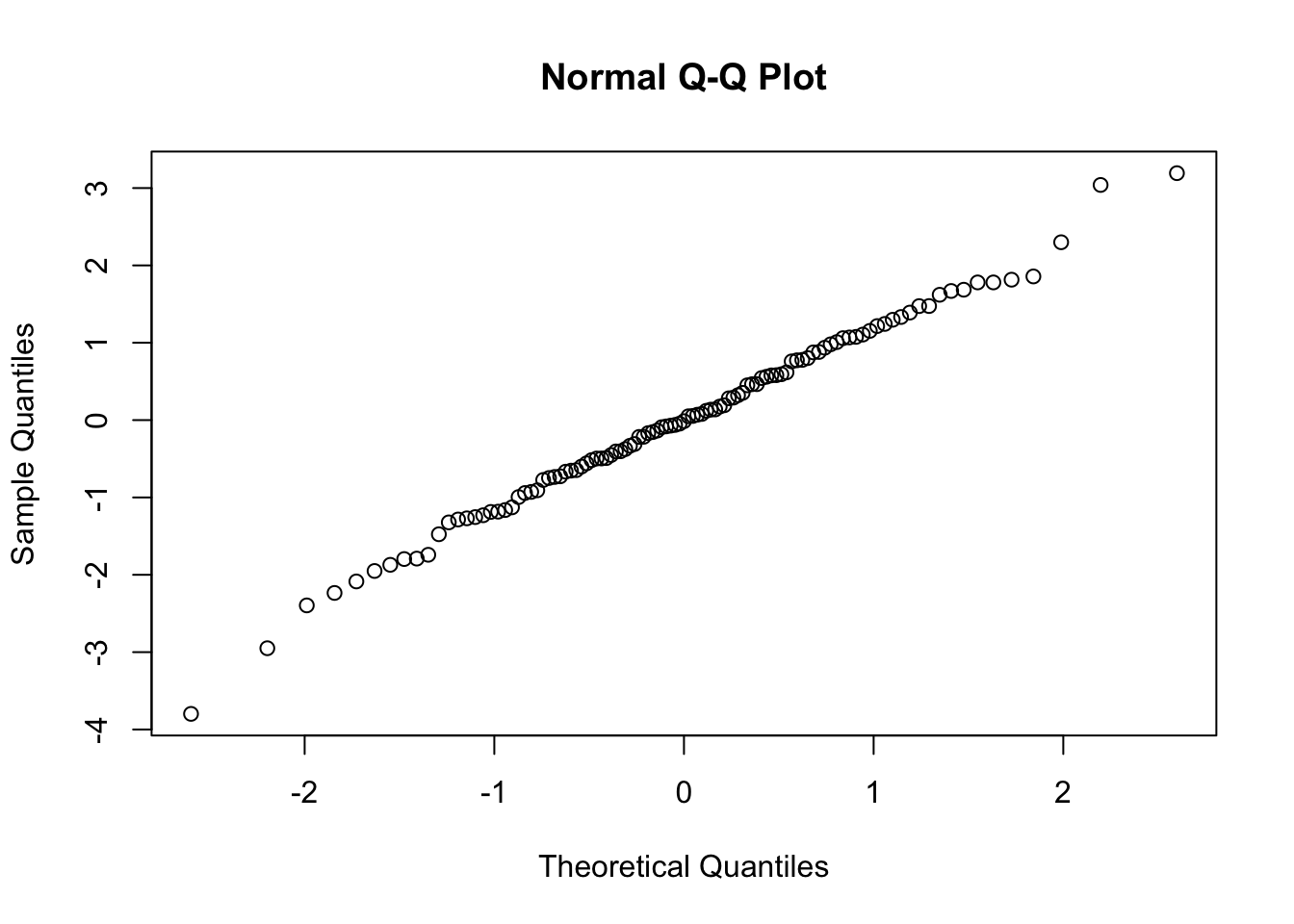
Examine the residuals… are they normally distributed?
##
## Call:
## lm(formula = log(HomeRange) ~ log(BodyMass) + log(BrainSize) +
## GroupSize + Move, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.7978 -0.6473 -0.0038 0.8807 2.1598
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -6.955853 1.957472 -3.553 0.000865 ***
## log(BodyMass) 0.315276 0.468439 0.673 0.504153
## log(BrainSize) 0.614460 0.591100 1.040 0.303771
## GroupSize 0.034026 0.009793 3.475 0.001095 **
## Move 0.025916 0.019559 1.325 0.191441
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.127 on 48 degrees of freedom
## (160 observations deleted due to missingness)
## Multiple R-squared: 0.6359, Adjusted R-squared: 0.6055
## F-statistic: 20.95 on 4 and 48 DF, p-value: 4.806e-10
Show Code
plot(m$residuals)
Show Code
qqnorm(m$residuals)
Show Code
shapiro.test(m$residuals)
Show Output
##
## Shapiro-Wilk normality test
##
## data: m$residuals
## W = 0.96517, p-value = 0.1242
When we plot effects for this model, note that the predictor effect plot uses untransformed predictor values on the horizontal axis, not the log-transformed variables that we used in the regression model.
We can use the “axes=” argument and the “x=” sub-argument to transform the horizontal axis, for example to replace BodyMass by log(BodyMass). The code below specifies a lot of tweaks to the x axis…
What happens if we remove the \(Move\) term from the model?
Show Code
m <-lm(data = d, log(HomeRange) ~log(BodyMass) +log(BrainSize) + GroupSize)summary(m)
Show Output
##
## Call:
## lm(formula = log(HomeRange) ~ log(BodyMass) + log(BrainSize) +
## GroupSize, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.7982 -0.7310 -0.0140 0.8386 3.1926
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -5.354845 1.176046 -4.553 1.45e-05 ***
## log(BodyMass) -0.181627 0.311382 -0.583 0.560972
## log(BrainSize) 1.390536 0.398840 3.486 0.000721 ***
## GroupSize 0.030433 0.008427 3.611 0.000473 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.228 on 103 degrees of freedom
## (106 observations deleted due to missingness)
## Multiple R-squared: 0.6766, Adjusted R-squared: 0.6672
## F-statistic: 71.85 on 3 and 103 DF, p-value: < 2.2e-16
Show Code
plot(m$residuals)
Show Code
qqnorm(m$residuals)
Show Code
shapiro.test(m$residuals) # no significant deviation from normal
Show Output
##
## Shapiro-Wilk normality test
##
## data: m$residuals
## W = 0.99366, p-value = 0.9058
21.9 Visualizing Model Results
We have already seen lots of ways to view linear modeling results, e.g., by using the summary(), glance(), and tidy() functions with model objects as arguments. The {jtools} package provides some interesting additional functions for summarizing and visualizing regression models results.
The summ() function is an alternative to summary() that provides a concise table of a model and its results. It can be used with standard lm() simple linear regression results (as we work with in this module) as well as with glm() and lmer() results (for generalized linear modeling and mixed effects modeling, respectively), as we cover in Module 23 and Module 24.
The effect_plot() function can be used to plot the relationship between (one of) the predictor variables and the response variable while holding the others constant. The function contains lots of possible arguments for customizing the plot, e.g., for specifying whether and what types of interval can be plotted.
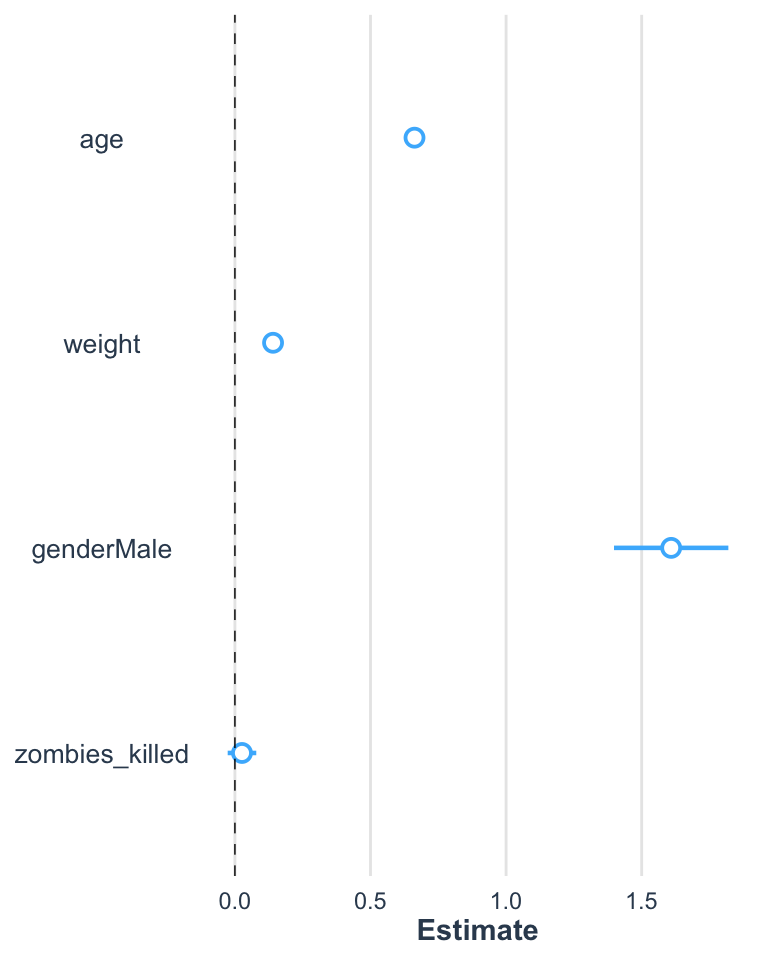
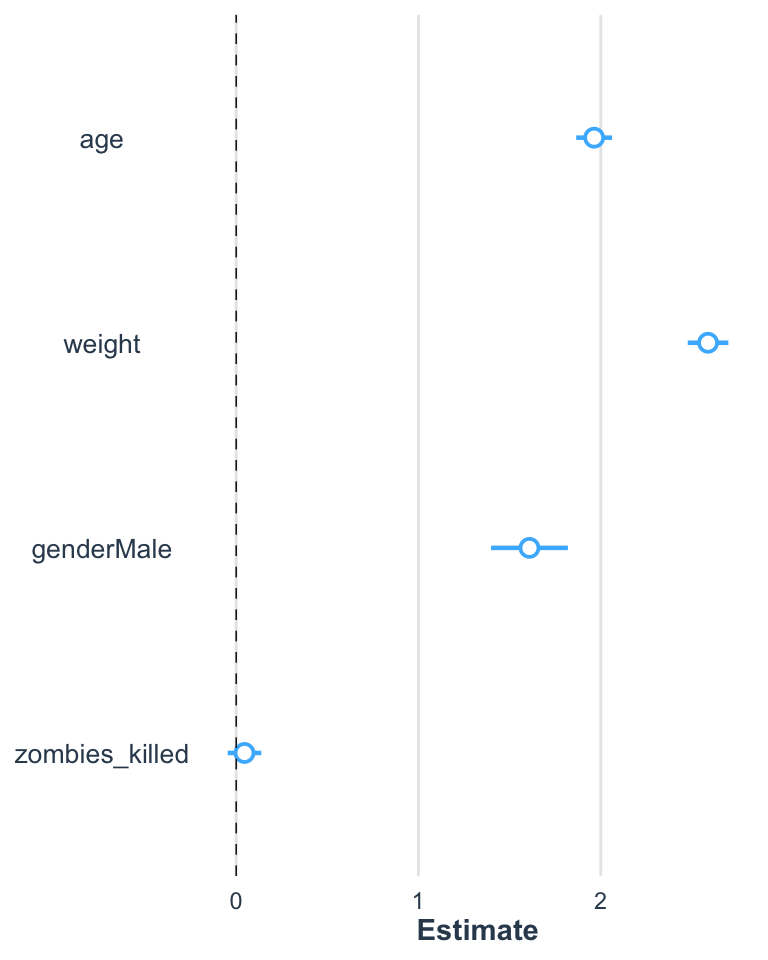
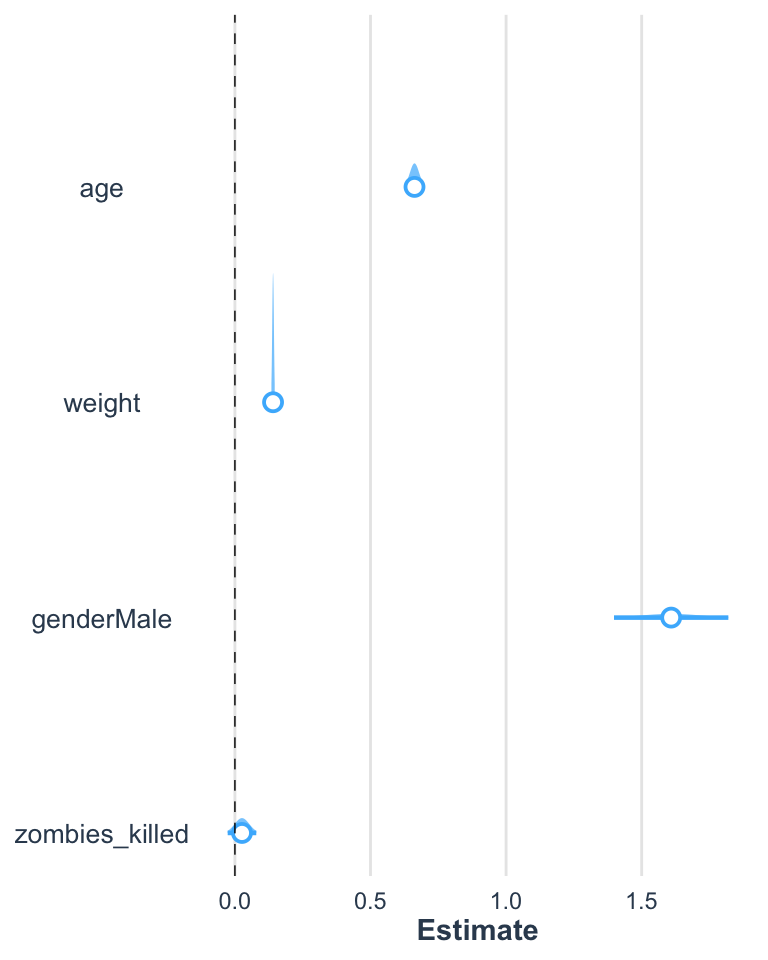
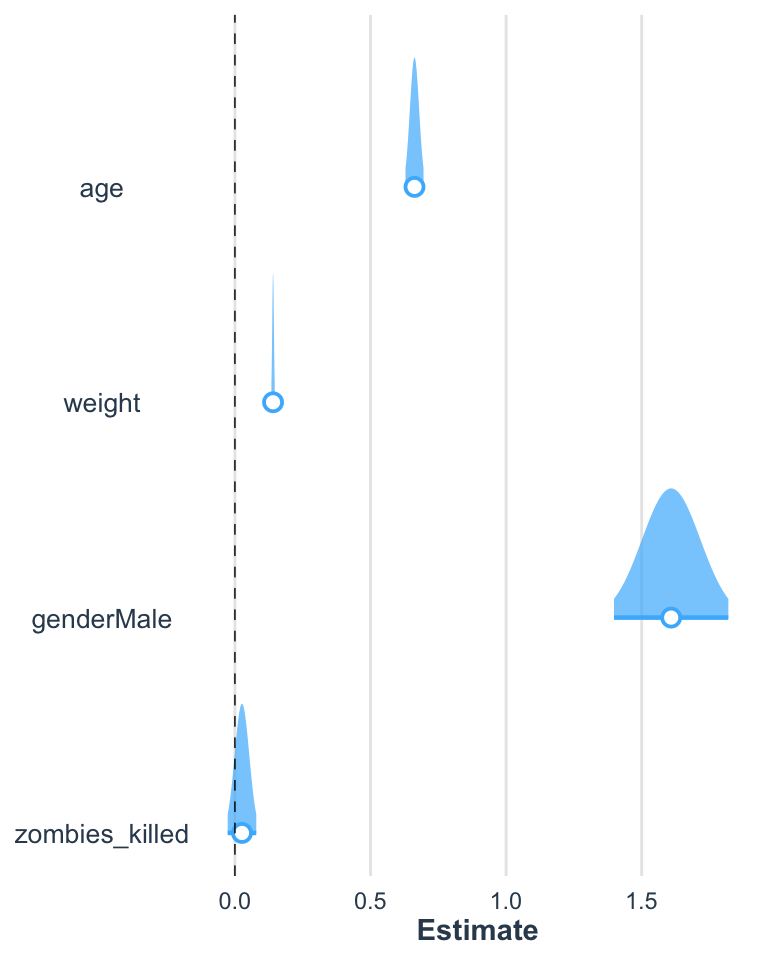
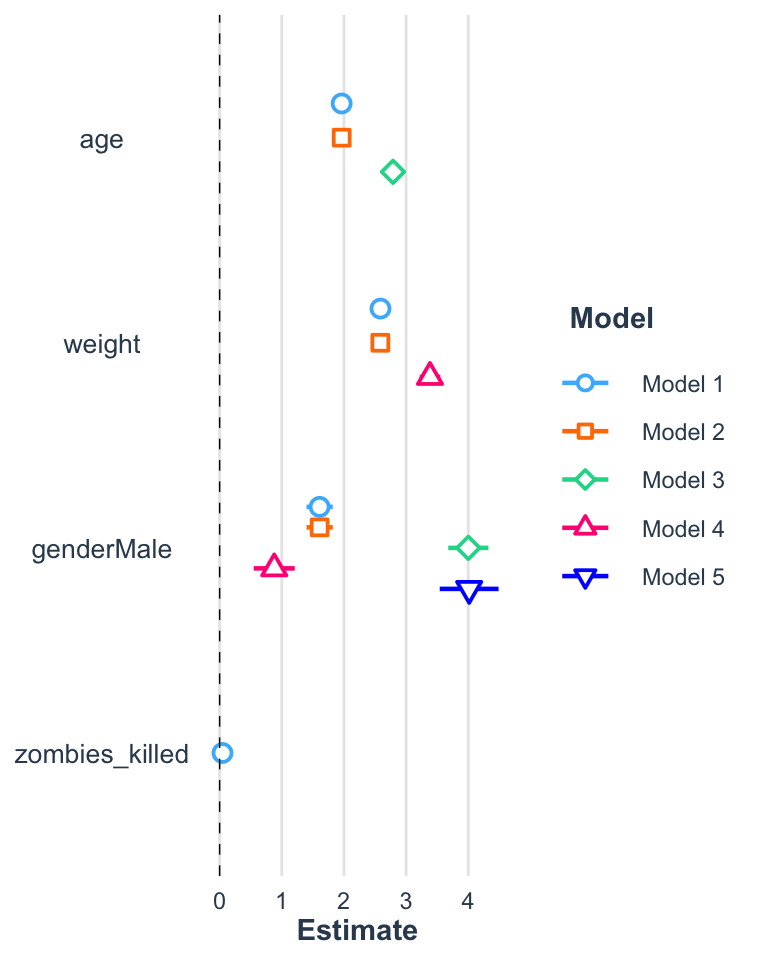
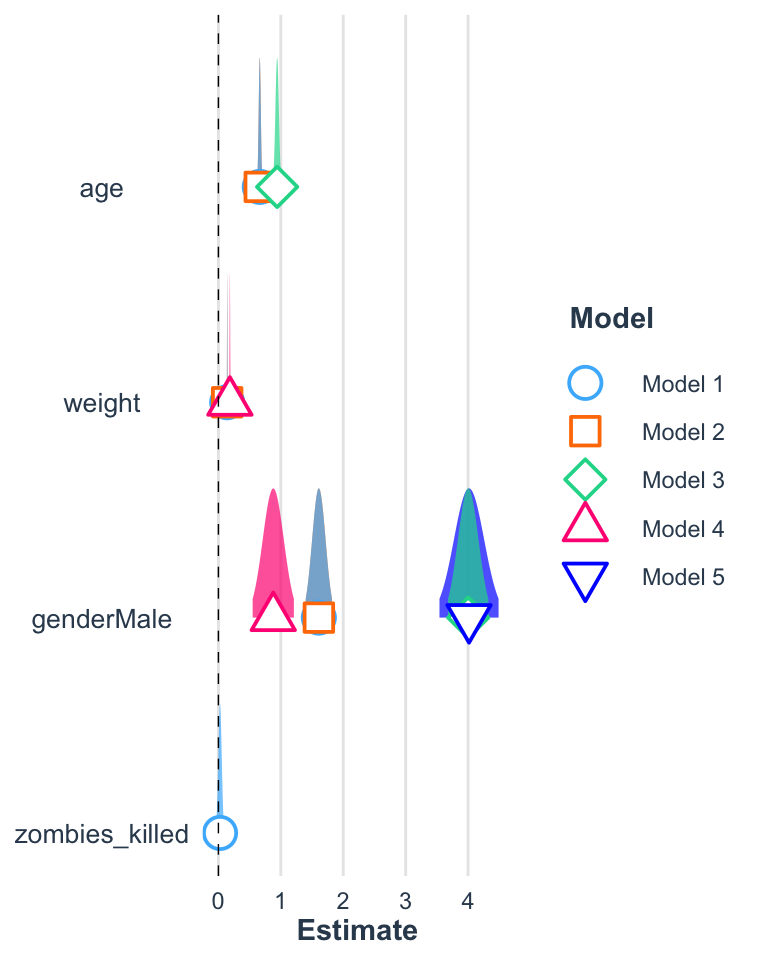
The plot_summs() function can be used to nicely visualize coefficient estimates and CI values around those terms, including visualizing multiple models on the same plot.
Let’s return to working with the zombie apocaluypse survivors dataset…
Multiple regression and ANCOVA are further extensions of simple linear regression/ANOVA to cases where we have more than one predictor variable
“Multiple regression” refers to where we have 2 or more continuous predictor variables
“ANCOVA” refers to cases where we have one or more continuous predictor variables and one or more categorical predictor variables
Source Code
# Multiple Regression and ANCOVA {#module-21}## Objectives> In this module, we extend our simple linear regression and ANOVA models to cases where we have more than one predictor variable. The same approach can be used with combinations of continuous and categorical variables. If all of our predictors variables are continuous, we typically describe this as "multiple linear regression". If our predictors are combinations of continuous and categorical variables, we typically describe this as "analysis of covariance", or ANCOVA.## Preliminaries- Install these packages in ***R***: [{jtools}](https://cran.r-project.org/web/packages/jtools/jtools.pdf)[{ggeffects}](https://cran.r-project.org/web/packages/ggeffects/ggeffects.pdf)- Install and load this package in ***R***:[{effects}](https://cran.r-project.org/web/packages/effects/effects.pdf)- Load {tidyverse}, {broom}, {car}, and {gridExtra}```{r}#| include: false#| message: falselibrary(tidyverse)library(broom)library(car)library(gridExtra)library(effects)```## OverviewMultiple linear regression and ANCOVA are pretty straightforward generalizations of the simple linear regression and ANOVA approach that we have considered previously (i.e., Model I regressions, with our parameters estimated using the criterion of OLS). In multiple linear regression and ANCOVA, we are looking to model a response variable in terms of more than one predictor variable so that we can evaluate the effects of several different explanatory variables. When we do multiple linear regression, we are, essentially, looking at the relationship between each of two or more continuous predictor variables and a continuous response variable **while holding the effect of all other predictor variables constant**. When we do ANCOVA, we are effectively looking at the relationship between one or more continuous predictor variables and a continuous response variable within each of one or more categorical groups.To characterize this using formulas analogous to those we have used before...Simple Bivariate Linear Model:$$Y = \beta_0 + \beta_1x + \epsilon$$Multivariate Linear Model:$$Y = \beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_kx_k + \epsilon$$We thus now need to estimate **several** $\beta$ coefficients for our regression model - one for the intercept plus one for each predictor variable in our model, and, instead of a "line"" of best fit, we are determining a multidimensional "surface" of best fit. The criteria we typically use for estimating best fit is analogous to that we've used before, i.e., **ordinary least squares**, where we want to minimize the multidimensional squared deviation between our observed and predicted values:$$\sum\limits_{i=1}^{k}[y_i - (\beta_0 + \beta_1x_{1_i} + \beta_2x_{2_i} + ... + \beta_kx_{k_i})]^2$$Estimating our set of coefficients for multiple regression is actually done using matrix algebra, which we do not need to explore thoroughly (but see the "digression" below). The `lm()` function will implement this process for us directly.> **NOTE:** Besides the least squares approach to parameter estimation, we might also use other approaches, including **maximum likelihood** and **Bayesian approaches.** These are mostly beyond the scope of what we will discuss in this class, but the objective is the same... to use a particular criterion to estimate parameter values for describing the relationship between our predictor and response variables, as well as for estimating the amount of uncertainty in those parameter values. It is worth noting that for many common population parameters (such as the mean), as well as for regression slopes and/or factor effects in certain linear models, OLS and ML estimators turn out to be exactly the same when the assumptions behind OLS are met (i.e., normally distributed variables and normally distributed error terms). When response variables or residuals are not normally distributed (e.g., where we have binary or categorical response variables), we use ML or Bayesian approaches, rather than OLS, for parameter estimation.Let's work some examples!## Multiple Regression#### Continous Response Variable with More than One Continuous Predictor {.unnumbered}We will start by taking a digression to construct a dataset ourselves of some correlated random normal continuous variables. The following bit of code will let us do that. [See also this post](https://www.r-bloggers.com/simulating-random-multivariate-correlated-data-categorical-variables/) for more information on generating toy data with a particular correlation structure. First, we define a matrix of correlations, **R**, among our variables (you can play with the values in this matrix, but it must be symmetric):```{r}R =matrix(cbind(1,0.80,-0.5,0.00,0.80,1,-0.3,0.3,-0.5,-0.3,1, 0.6,0.00,0.3,0.6,1), nrow=4)R```Second, we generate a dataset of random normal variables where each has a defined mean and standard deviation and then bundle these into a dataframe ("original"):```{r}n <-1000k <-4original <-NULLv <-NULLmu <-c(15,40,5,23) # vector of variable meanss <-c(5,20,4,15) # vector of variable SDsfor (i in1:k){ v <-rnorm(n,mu[i],s[i]) original <-cbind(original,v)}original <-as.data.frame(original)names(original) =c("Y","X1","X2","X3")head(original)cor(original) # variables are uncorrelated# make quick bivariate plots for each pair of variablesplot(original)# using `pairs(original)` would do the same```Now, let's normalize and standardize our variables by subtracting the relevant means and dividing by the standard deviation. This converts them to $Z$ scores from a standard normal distribution.Now run the following... note how we use the `apply()` and `sweep()` functions here. Cool, eh?```{r}means <-apply(original, 2, FUN ="mean") # returns a vector of means, where we are taking this across dimension 2 of the array "orig"means# ormeans <-unlist(summarize(original, ymean =mean(Y), x1mean=mean(X1),x2mean=mean(X2),x3mean=mean(X3)))msstdevs <-apply(original, 2, FUN ="sd")stdevs# orstdevs <-unlist(summarize(original, ySD =sd(Y), x1SD=sd(X1),x2SD=sd(X2),x3SD=sd(X3)))stdevsnormalized <-sweep(original,2,STATS=means,FUN="-") # 2nd dimension is columns, removing array of means, function = subtractnormalized <-sweep(normalized,2,STATS=stdevs,FUN="/") # 2nd dimension is columns, scaling by array of sds, function = dividehead(normalized) # now a dataframe of Z scoresplot(normalized)M <-as.matrix(normalized) # define M as our matrix of normalized variables```With `apply()`, we apply a function to a specified margin of an array or matrix (`1` = row, `2` = column), and with `sweep()` we then perform whatever function is specified by `FUN=` on all of the elements in an array specified by the given margin.Next, we take what is called the Cholesky decomposition of our correlation matrix, **R**, and then multiply our normalized data matrix by the decomposition matrix to yield a transformed dataset with the specified correlation among variables. The Cholesky decomposition breaks certain symmetric matrices into two such that:$R = U \cdot U^T$```{r}U =chol(R)newM = M %*% Unew =as.data.frame(newM)names(new) =c("Y","X1","X2","X3")cor(new) # note that is correlation matrix is what we are aiming for!plot(original)plot(new) # note the axis scales; using `pairs(new)` would plot the same```Finally, we can scale these back out to the mean and distribution of our original random variables.```{r}d <-sweep(new,2,STATS=stdevs, FUN="*") # scale back out to original mean...d <-sweep(d,2,STATS=means, FUN="+") # and standard deviationhead(d)cor(d)plot(d) # note the change to the axis scales# using `pairs(d)` would produce the same plot```We now have our own dataframe, **d**, comprising correlated random variables in original units!Let's explore this dataset, first with single and then with multivariate regression.### CHALLENGE {.unnumbered}Start off by making three bivariate scatterplots in {ggplot2} using the dataframe of three predictor variables (**X1**, **X2**, and **X3**) and one response variable (**Y**) that we generated above (or download it from "https://raw.githubusercontent.com/difiore/ada-datasets/main/multiple_regression.csv")```{r}f <-"https://raw.githubusercontent.com/difiore/ada-datasets/main/multiple_regression.csv"d <-read_csv(f, col_names =TRUE)``````{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'g1 <-ggplot(data=d, aes(x = X1, y = Y)) +geom_point() +geom_smooth(method="lm", formula=y~x)g2 <-ggplot(data=d, aes(x = X2, y = Y)) +geom_point() +geom_smooth(method="lm", formula=y~x)g3 <-ggplot(data=d, aes(x = X3, y = Y)) +geom_point() +geom_smooth(method="lm", formula=y~x)grid.arrange(g1, g2, g3, ncol=3)```Then, using simple linear regression as implemented with `lm()`, how does the response variable (**Y**) vary with each predictor variable (**X1**, **X2**, **X3**)? Are the $\beta_1$ coefficients for each bivariate significant? How much of the variation in **Y** does each predictor explain in a simple bivariate linear model?```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'m1 <-lm(data = d, formula = Y ~ X1)summary(m1)m2 <-lm(data = d, formula = Y ~ X2)summary(m2)m3 <-lm(data = d, formula = Y ~ X3)summary(m3)```In simple linear regression, **Y** has a significant, positive relationship with **X1**, a signficant negative relationship with **X2**, and no significant bivariate relationship with **X3**.Now let's move on to doing actual multiple regression. To review, with multiple regression, we are looking to model a response variable in terms of two or more predictor variables so we can evaluate the effect of each of several explanatory variables while holding the others constant.Using `lm()` and formula notation, we can fit a model with all three predictor variables. The `+` sign is used to add additional predictors to our model.```{r}m <-lm(data = d, formula = Y ~ X1 + X2 + X3)coef(m)summary(m)```Next, let's check if our residuals are random normal...```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'plot(fitted(m), residuals(m))hist(residuals(m))qqnorm(residuals(m))qqline(residuals(m))```What does this output tell us? First off, the results of the omnibus F test tells us that the overall model is significant; using these three variables, we explain signficantly more of the variation in the response variable, **Y**, than we would using a model with just an intercept, i.e., just that $Y$ = mean($Y$).For a multiple regression model, we calculate the F statistic as follows:$$F = \frac{R^2(n-p-1)}{(1-R^2)p}$$where...- $R^2$ = multiple R squared value- $n$ = number of data points- $p$ = number of parameters estimated from the data (i.e., the number of $\beta$ coefficients, not including the intercept)```{r}f <- (summary(m)$r.squared * (nrow(df) - (ncol(df) -1) -1)) / ((1-summary(m)$r.squared) * (ncol(df) -1))f```Is this F ratio significant?```{r}1-pf(q = f, df1 =nrow(df) - (ncol(df) -1) -1, df2 =ncol(df) -1)```Second, looking at `summary()` we see that the $\beta$ coefficient for each of our predictor variables (including **X3**) is significant. That is, each predictor is significant even when the effects of the other predictor variables are held constant. Recall that in the simple linear regression, the $\beta$ coefficient for **X3** was not significant.Third, we can interpret our $\beta$ coefficients as we did in simple linear regression... for each change of one unit in a particular predictor variable (holding the other predictors constant), our predicted value of the response variable changes $\beta$ units.### Plotting EffectsWe can use the versatile {effects} package to visualize the results of a variety of model objects, include general and generalized linear models and mixed effects models. The function `predictorEffects()` with no arguments will display the linear relationship between the response variable and each predictor.```{r}plot(predictorEffects(m))```We can also specify particular predictors we wish to look at by adding the "predictors = ~" argument...```{r}plot(predictorEffects(m, predictors =~ X1))```Specifying the argument "partial.residuals = TRUE" returns the same plots as above, plus the values of the residuals after subtracting off the contribution from all other explanatory variables as well as a loess smoothed line of best fit through the residuals. Such plots are useful for detecting, for example, nonlinear relationships or interactions between predictors that are not obvious from looking at the original data.```{r}plot(predictorEffects(m, partial.residuals =TRUE))```The {ggeffects} package allows us to similarly predict and plot marginal effects from a model object. The `predict_response()` function takes a *model* object and one or more focal *terms* and returns the predicted values for the response variable across values of the focal term, along a specified margin ("mean_reference" by default) for the nonfocal terms. These can then be plotted with the `plot()` function.```{r}library(ggeffects)p <-predict_response(m, "X1 [all]")plot(p)plot(p, show_data =TRUE, jitter =0.1) # superimpose original dataplot(p, show_residuals =TRUE, show_residuals_line =TRUE, jitter =0.1) # superimpose residuals and loess smoothed line of best fitdetach(package:ggeffects)```### CHALLENGE {.unnumbered}Load up the "zombies.csv" dataset with the characteristics of zombie apocalypse survivors again and run a linear model of height as a function of both weight and age. Is the overall model significant? Are both predictor variables significant when the other is controlled for? Make effects plots for each variable, plotting the partial residuals and the loess smoothed relationship between the residuals and each predictor.```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'f <-"https://raw.githubusercontent.com/difiore/ada-datasets/main/zombies.csv"d <-read_csv(f, col_names =TRUE)head(d)m <-lm(data = d, height ~ weight + age)summary(m)plot(predictorEffects(m, partial.residuals =TRUE))```## ANCOVA#### Continous Response Variable with both Continuous and Categorical Predictors {.unnumbered}We can use the same linear modeling approach to do **analysis of covariance**, or ANCOVA, where we have a continuous response variable and a combination of continuous and categorical predictor variables. Let's return to the "zombies.csv" dataset and now include one continuous and one categorical variable in our model... we want to predict height as a function of **age** (a continuous variable) and **gender** (a categorical variable), and we want to use Type II regression (because we have an unbalanced design). What is our model formula?```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'d$gender <-factor(d$gender)m <-lm(data = d, formula = height ~ gender + age)summary(m)m.aov <-Anova(m, type ="II")m.aovplot(fitted(m), residuals(m))hist(residuals(m))qqnorm(residuals(m))qqline(residuals(m))```How do we interpret these results?- The omnibus F test is significant- Both predictors are significant- Height is related to age when sex is controlled for- Controlling for age, being **male** adds ~4 inches to predicted height when compared to being female.#### Visualizing a Parallel Slopes Model {.unnumbered}We can now write two equations for the relationship between height, on the one hand, and age and gender on the other:For females...$$height = 46.7251 + 0.94091 \times age$$> In this case, females are the first level of our "gender" factor and thus do not have additional regression coefficients associated with them.For males...$$height = 46.7251 + 4.00224 + 0.94091 \times age$$> Here, the additional 4.00224 added to the intercept term is the coefficient associated with **genderMale**```{r}p <-ggplot(data = d, aes(x = age, y = height)) +geom_point(aes(color =factor(gender))) +scale_color_manual(values =c("red", "blue"))p <- p +geom_abline(slope = m$coefficients[3],intercept = m$coefficients[1],color ="darkred" )p <- p +geom_abline(slope = m$coefficients[3],intercept = m$coefficients[1] + m$coefficients[2],color ="darkblue" )p```Note that this model is based on all of the data collectively... we are not doing separate linear models for males and females, which *could* result in different intercepts and slopes for each sex... rather, we are modeling both sexes as having the same slope but different intercepts. This is what is known as a "parallel slopes" model. Below, we will explore a model where we posit an **interaction** between age and sex, which would require estimation of four separate parameters (i.e., both a slope *and* an intercept for males *and* females rather than, as above, only different intercepts for males and females but the same slope for each sex).Using the `confint()` function on our ANCOVA model results reveals the confidence intervals for each of the coefficients in our multiple regression, just as it did for simple regression.```{r}confint(m, level =0.95)```We can also generate effects plots for this ANCOVA model:```{r}plot(predictorEffects(m, partial.residuals =TRUE))```## Multicollinearity and VIFsWhen we have more than one explanatory variable in a regression model, we need to be concerned about possible high inter-correlations those variables. One way to characterize the amount of multicollinearity is by examining the variance inflation factor, or **VIF**, for each variable. Mathematically, the VIF for a predictor variable *i* is calculated as:$$\frac{1}{1-R_i^2}$$where $R_i^2$ is the R-squared value for the regression of variable *i* on all other predictors. A high VIF indicates that the predictor is highly collinear with other predictors in the model. As a rule of thumb, a VIF value that exceeds ~5 indicates a problematic amount of multicollinearity. The function `vif()` from the {car} package provides one way to calculate VIFs.Below, we set up a new model with three predictors, **weight**, **age**, and **gender**, and calculate VIFs:```{r}m <-lm(height ~ weight + age + gender, data = d)summary(m)vif(m)```We can also calculate VIFs manually, by running models that regress each individual predictor on all of the others...```{r}w <-lm(weight ~ gender + age, data = d)rsq_w <-summary(w)$r.square(vif_w <-1/(1-rsq_w))a <-lm(age ~ gender + weight, data = d)rsq_a <-summary(a)$r.square(vif_a <-1/(1-rsq_a))# for a categorical predictor variable, we can coerce it to numeric to use it as a response variableg <-lm(as.numeric(gender) ~ age + weight, data = d)rsq_g <-summary(g)$r.square(vif_g <-1/(1-rsq_g))```## Confidence and Prediction IntervalsOne common reason for fitting a regression model is to then use that model to predict the value of the response variable under particular combinations of values of predictor variables, i.e., to predict the values of new observations. We can think of the **Y** value predicted by the regression model ($\hat{y}$) as a point estimate of the response variable given particular value(s) of the predictor variable(s). This point estimate is associated with some uncertainty, which we can characterize in terms of either **confidence intervals** or **prediction intervals** around each the estimate. CIs represent uncertainty about the **mean value** of the response variable for a given (combination of) predictor value(s), while PIs represent our uncertainty about **actual new predicted values** of the response variable at those predictor value(s).The `predict()` allows us to determine these intervals for individual responses for a given combination of predictor variables. `predict()` takes as arguments a model object, new values for the predictor(s) to be plugged into the model, an interval type ("confidence" or "prediction"), and a confidence level (e.g., "0.95").### CHALLENGE {.unnumbered}Let's return to our model of height as a function of age and gender:```{r}m <-lm(height ~ age + gender, data = d)```- What is the predicted mean height, in inches, for 29-year old males who have survived the zombie apocalypse? What is the 95% confidence interval around this predicted mean height?```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'ci <-predict(m, newdata =data.frame(age =29, gender ="Male"),interval ="confidence", level =0.95)ci```- What is the 95% prediction interval for the *individual* heights of 29-year old male zombie apocalypse survivors?```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'pi <-predict(m, newdata=data.frame(age =29, gender ="Male"),interval="prediction",level=0.95)pi```In general, the width of a confidence interval for $\hat{y}$ increases as the value of our predictor variables moves away from the center of their distribution. Also, although both are intervals are centered at $\hat{y}$, the predicted mean value of the response variable for the given (combination of) predictor(s), the prediction interval is invariably wider than the confidence interval. This makes intuitive sense, since the prediction interval encapsulates the possibility for individual values of **Y** to fluctuate away from the predicted mean value, while the confidence interval describes uncertainty in estimates of the predicted mean value. That is, the estimate of the mean of a variable is expected to be less uncertain than estimates of individual variable values, because the mean is already a statistic that summarizes a set of values.We can see this by generating CIs and PIs for a range of data using the `predict()` function. Below, we pass `predict()` a new set of 1000 values ranging from the minimum to the maximum male age in our original data set...```{r}males <- d |>filter(gender =="Male")new_x <-seq(from =min(males$age), to =max(males$age), length.out =1000)ci <-predict( m,newdata =data.frame(age = new_x, gender ="Male"),interval ="confidence", level =0.95)ci <-tibble(x = new_x, as_tibble(ci))pi <-predict( m, newdata =data.frame(age = new_x, gender ="Male"),interval ="prediction",level =0.95)pi <-as_tibble(pi)pi <-tibble(x = new_x, as_tibble(pi))p <-ggplot(data = d |>filter(gender =="Male"),aes(x = age, y = height)) +geom_point() +geom_line(data = ci, aes(x = x, y = fit), color ="red") +geom_line(data = ci, aes(x = x, y= lwr), color ="blue") +geom_line(data = ci, aes(x = x, y= upr), color ="blue") +geom_line(data = pi, aes(x = x, y= lwr), color ="green") +geom_line(data = pi, aes(x = x, y= upr), color ="green")p```An easier, alternative way to generate CIs and PIs for across a range of predictor values iswith the `augment()` function from {broom}, as it returns a "tibble" with fitted values and interval limits appended to the original data frame.```{r}ci <-augment( m,data = d,interval =c("confidence"))pi <-augment( m,data = d,interval =c("prediction"))p <-ggplot(data = ci |>filter(gender =="Male"), aes(x = age, y = height)) +geom_point() +geom_line(aes(x = age, y = .fitted), color ="red") +geom_ribbon(aes(x = age, ymin = .lower, ymax=.upper), alpha =0.5) +geom_ribbon(data = pi |>filter(gender =="Male"), aes(x = age, ymin = .lower, ymax=.upper), alpha =0.1)p```## Interactions Between PredictorsSo far, we have only considered the joint **main effects** of multiple predictors on a response variable, but often there are **interactive effects** between our predictors. An interactive effect is an additional change in the response that occurs because of particular combinations of predictors or because the relationship of one continuous variable to a response is contingent on a particular level of a categorical variable. We explored the former case a bit when we looked at ANOVAs involving two discrete predictors. Now, we'll consider the latter case... is there an interactive effect of sex **AND** age on height in our population of zombie apocalypse survivors?Using formula notation, it is easy for us to consider interactions between predictors. The colon (`:`) operator allows us to specify particular interactions we want to consider. We can also use the asterisk (`*`) operator to specify a full model, i.e., *all* single terms factors and *all* their interactions.What are the formula and results for a linear model of height as a function of age and sex plus the interaction of age and sex?```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'m <-lm(data = d, height ~ age + gender + age:gender)summary(m)# orm <-lm(data = d, height ~ age * gender)summary(m)coefficients(m)```Here, when we allow an interaction, there is no main effect of gender, but there is an interaction effect of gender and age.If we want to visualize this...$$ female\ height = 48.1817041 + 0.8891281 \times age$$ $$ male\ height = 48.1817041 + + 1.1597481 + 0.1417928 \times age$$```{r}p1 <-ggplot(data = d,aes(x = age, y = height)) +geom_point(aes(color =factor(gender))) +scale_color_manual(values =c("red","blue"))p1 <- p1 +geom_abline(slope = m$coefficients[2],intercept = m$coefficients[1], color ="darkred")p1 <- p1 +geom_abline(slope = m$coefficients[2] + m$coefficients[4],intercept = m$coefficients[1] + m$coefficients[3], color="darkblue")p1# or, using `geom_smooth()`...p2 <-ggplot(data = d,aes(x = age, y = height)) +geom_point(aes(color=factor(gender))) +scale_color_manual(values =c("red","blue")) +geom_smooth(method ="lm", aes(color =factor(gender)))p2```The `predictorEffects()` function from {effects} provides and alternative way to visualize interactions...```{r}plot(predictorEffects(m, predictors =~ age))plot(predictorEffects(m, predictors =~ gender))```In the case of **gender**, the function plots the difference in predicted **height** of females and males as a set of levels specified by the argument "xlevels=". The argument can be set to a particular number of levels (which is 5 by default, as in the example above) or it can be passed a list with elements named for the predictors, with either the number of level or a vector of level values added.```{r}plot(predictorEffects(m, predictors =~ gender, xlevels =list(age =6))) # 6 ages, spanning the range of ages in the datasetplot(predictorEffects(m, predictors =~ gender, xlevels =list(age =c(10, 15, 20)))) # 3 ages, specified by the user```### CHALLENGE {.unnumbered}- Load in the "KamilarAndCooper.csv"" dataset we have used previously- Reduce the dataset to the following variables: **Family**, **Brain_Size_Female_Mean**, **Body_mass_female_mean**, **MeanGroupSize**, **DayLength_km**, **HomeRange_km2**, and **Move** and assign **Family** to be a factor. Also, rename the brain size, body mass, group size, day length, and home range variables as **BrainSize**, **BodyMass**, **GroupSize**, **DayLength**, **HomeRange**```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'f <-"https://raw.githubusercontent.com/difiore/ada-datasets/main/KamilarAndCooperData.csv"d <-read_csv(f, col_names =TRUE)d$Family <-factor(d$Family)head(d)d <- d |>select(Brain_Size_Female_Mean, Family, Body_mass_female_mean, MeanGroupSize, DayLength_km, HomeRange_km2, Move) |>rename(BrainSize = Brain_Size_Female_Mean,BodyMass = Body_mass_female_mean,GroupSize = MeanGroupSize,DayLength = DayLength_km,HomeRange = HomeRange_km2)```- Fit a **Model I** least squares multiple linear regression model using log(**HomeRange**) as the response variable and log(**BodyMass**), log(**BrainSize**), **GroupSize**, and **Move** as predictor variables, and view a model summary.- Look at and interpret the estimated regression coefficients for the fitted model and interpret. Are any of them statistically significant? What can you infer about the relationship between the response and predictors?- Report and interpret the coefficient of determination and the outcome of the omnibus F test.- Examine the residuals... are they normally distributed?```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'m <-lm(data = d, log(HomeRange) ~log(BodyMass) +log(BrainSize) + GroupSize + Move)summary(m)plot(m$residuals)qqnorm(m$residuals)shapiro.test(m$residuals)```When we plot effects for this model, note that the predictor effect plot uses untransformed predictor values on the horizontal axis, not the log-transformed variables that we used in the regression model.```{r}plot(predictorEffects(m, partial.residuals =TRUE))```We can use the "axes=" argument and the "x=" sub-argument to transform the horizontal axis, for example to replace **BodyMass** by **log(BodyMass)**. The code below specifies a lot of tweaks to the x axis...```{r}plot(predictorEffects(m, ~ BodyMass, partial.residuals =TRUE),axes =list(x =list(rotate =90,BodyMass =list(transform =list(trans = log, inverse = exp),lab ="log(Body Mass)",ticks=list(at =c(100, 1000, 10000, 100000)),lim =c(100,100000) )) ))```- What happens if we remove the $Move$ term from the model?```{r}#| code-fold: true#| code-summary: "Show Code"#| attr.output: '.details summary="Show Output"'m <-lm(data = d, log(HomeRange) ~log(BodyMass) +log(BrainSize)+ GroupSize)summary(m)plot(m$residuals)qqnorm(m$residuals)shapiro.test(m$residuals) # no significant deviation from normal```## Visualizing Model ResultsWe have already seen lots of ways to view linear modeling results, e.g., by using the `summary()`, `glance()`, and `tidy()` functions with model objects as arguments. The {jtools} package provides some interesting additional functions for summarizing and visualizing regression models results.- The `summ()` function is an alternative to `summary()` that provides a concise table of a model and its results. It can be used with standard `lm()` simple linear regression results (as we work with in this module) as well as with `glm()` and `lmer()` results (for generalized linear modeling and mixed effects modeling, respectively), as we cover in [**Module 23**](#module-23) and [**Module 24**](#module-24).- The `effect_plot()` function can be used to plot the relationship between (one of) the predictor variables and the response variable while holding the others constant. The function contains lots of possible arguments for customizing the plot, e.g., for specifying whether and what types of interval can be plotted.- The `plot_summs()` function can be used to nicely visualize coefficient estimates and CI values around those terms, including visualizing multiple models on the same plot.Let's return to working with the zombie apocaluypse survivors dataset...```{r}#| message: false#| fig-width: 4f <-"https://raw.githubusercontent.com/difiore/ada-datasets/main/zombies.csv"d <-read_csv(f, col_names =TRUE)library(jtools)m1 <-lm(data = d, height ~ age + weight + gender + zombies_killed)summ(m1, confint =TRUE, ci.width =0.95, digits =3)effect_plot(m1, pred = age, interval =TRUE, int.type ="confidence",int.width =0.95, plot.points =TRUE)m2 <-lm(data = d, height ~ age + weight + gender)m3 <-lm(data = d, height ~ age + gender)m4 <-lm(data = d, height ~ weight + gender)m5 <-lm(data = d, height ~ gender)# plot with unstandardized beta coefficientsplot_summs(m1)# plot with standardized beta coefficients# (i.e., mean centers the variables and sets SD to 1)plot_summs(m1, scale =TRUE) # plot with 95% CIs and distributionsplot_summs(m1, plot.distributions =TRUE)# plot with 95% CIs and distributions scaled to same heightplot_summs(m1, plot.distributions =TRUE, rescale.distributions =TRUE)# plot multiple modelsplot_summs(m1, m2, m3, m4, m5, scale =TRUE)# plot multiple modelsplot_summs(m1, m2, m3, m4, m5, plot.distributions =TRUE, rescale.distributions =TRUE)detach(package:jtools)``````{r}#| include: falsedetach(package:effects)detach(package:gridExtra)detach(package:car)detach(package:broom)detach(package:tidyverse)```---## Concept Review {.unnumbered}- Multiple regression and ANCOVA are further extensions of simple linear regression/ANOVA to cases where we have more than one predictor variable- "Multiple regression" refers to where we have 2 or more continuous predictor variables- "ANCOVA" refers to cases where we have one or more continuous predictor variables and one or more categorical predictor variables